nlmixr
Running PK models with nlmixr
nlmixr uses a unified interface for specifying and running models. Let’s start with a very simple PK example, using the single-dose theophylline dataset generously provided by Dr. Robert A. Upton of the University of California, San Francisco:
## Load libraries
library(ggplot2)
library(nlmixr)
str(theo_sd)
#> 'data.frame': 144 obs. of 7 variables:
#> $ ID : int 1 1 1 1 1 1 1 1 1 1 ...
#> $ TIME: num 0 0 0.25 0.57 1.12 2.02 3.82 5.1 7.03 9.05 ...
#> $ DV : num 0 0.74 2.84 6.57 10.5 9.66 8.58 8.36 7.47 6.89 ...
#> $ AMT : num 320 0 0 0 0 ...
#> $ EVID: int 101 0 0 0 0 0 0 0 0 0 ...
#> $ CMT : int 1 2 2 2 2 2 2 2 2 2 ...
#> $ WT : num 79.6 79.6 79.6 79.6 79.6 79.6 79.6 79.6 79.6 79.6 ...
ggplot(theo_sd, aes(TIME, DV)) + geom_line(aes(group=ID), col="red") +
scale_x_continuous("Time (h)") + scale_y_continuous("Concentration") +
labs(title="Theophylline single-dose", subtitle="Concentration vs. time by individual")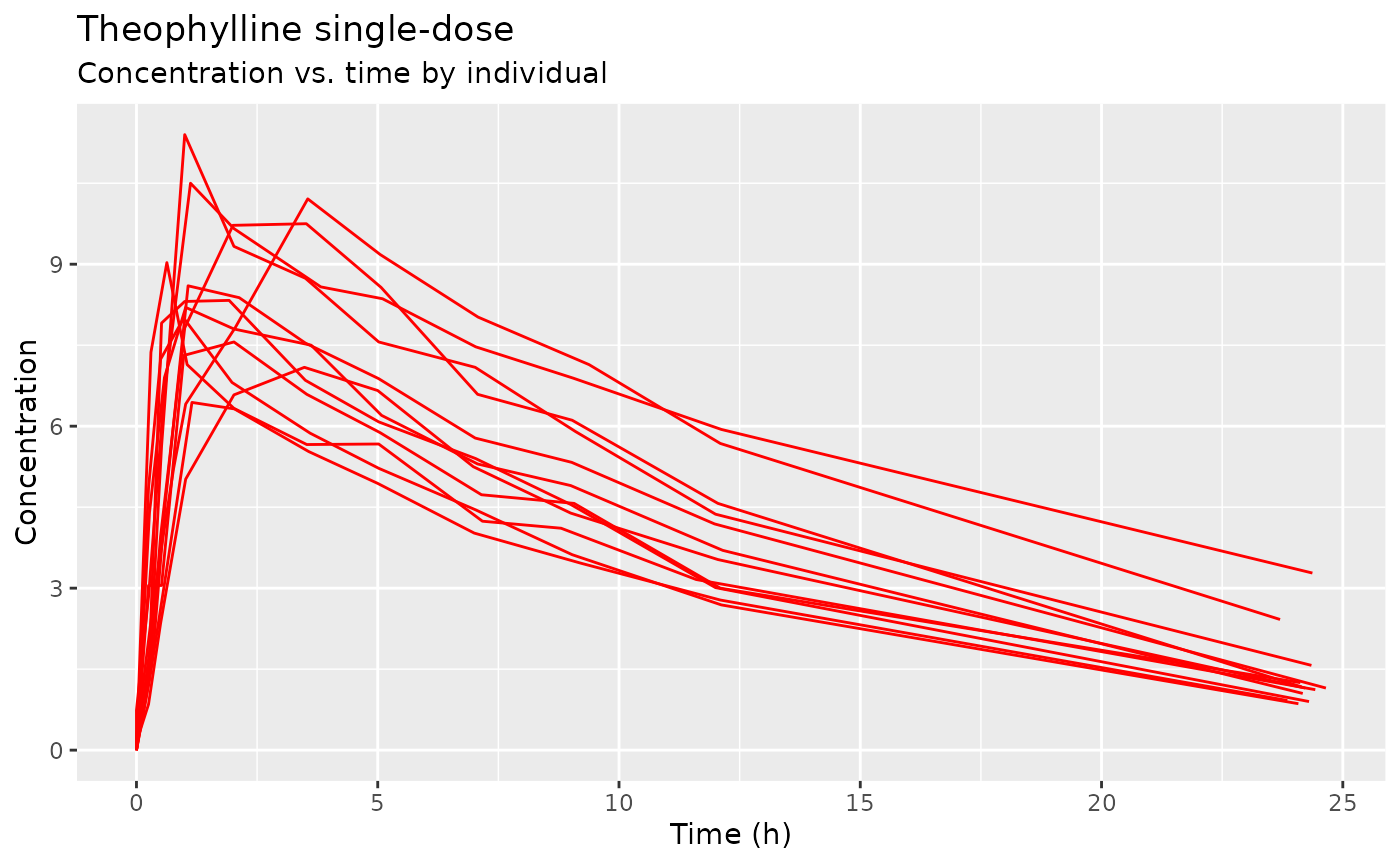
We can try fitting a simple one-compartment PK model to this small dataset. We write the model as follows:
one.cmt <- function() {
ini({
## You may label each parameter with a comment
tka <- 0.45 # Log Ka
tcl <- log(c(0, 2.7, 100)) # Log Cl
## This works with interactive models
## You may also label the preceding line with label("label text")
tv <- 3.45; label("log V")
## the label("Label name") works with all models
eta.ka ~ 0.6
eta.cl ~ 0.3
eta.v ~ 0.1
add.sd <- 0.7
})
model({
ka <- exp(tka + eta.ka)
cl <- exp(tcl + eta.cl)
v <- exp(tv + eta.v)
linCmt() ~ add(add.sd)
})
}
f <- nlmixr(one.cmt)We can now run the model…
fit <- nlmixr(one.cmt, theo_sd, list(print=0), est="focei")
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> calculating covariance matrix
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#> done
print(fit)
#> ── nlmixr FOCEi (outer: nlminb) fit ────────────────────────────────────────────
#>
#> OBJF AIC BIC Log-likelihood Condition Number
#> FOCEi 116.8035 373.4033 393.5829 -179.7016 68.42019
#>
#> ── Time (sec $time): ───────────────────────────────────────────────────────────
#>
#> setup optimize covariance table other
#> elapsed 5.800482 0.199363 0.199371 0.018 0.686784
#>
#> ── Population Parameters ($parFixed or $parFixedDf): ───────────────────────────
#>
#> Parameter Est. SE %RSE Back-transformed(95%CI) BSV(CV%) Shrink(SD)%
#> tka Log Ka 0.464 0.195 42.1 1.59 (1.08, 2.33) 70.4 1.81%
#> tcl Log Cl 1.01 0.0751 7.42 2.75 (2.37, 3.19) 26.8 3.87%
#> tv log V 3.46 0.0437 1.26 31.8 (29.2, 34.6) 13.9 10.3%
#> add.sd 0.695 0.695
#>
#> Covariance Type ($covMethod): r,s
#> Some strong fixed parameter correlations exist ($cor) :
#> cor:tcl,tka cor:tv,tka cor:tv,tcl
#> 0.158 0.422 0.744
#>
#>
#> No correlations in between subject variability (BSV) matrix
#> Full BSV covariance ($omega) or correlation ($omegaR; diagonals=SDs)
#> Distribution stats (mean/skewness/kurtosis/p-value) available in $shrink
#> Minimization message ($message):
#> relative convergence (4)
#>
#> ── Fit Data (object is a modified tibble): ─────────────────────────────────────
#> # A tibble: 132 × 20
#> ID TIME DV PRED RES WRES IPRED IRES IWRES CPRED CRES
#> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 0 0.74 1.79e-15 0.740 1.07 0 0.74 1.07 -5.61e-16 0.740
#> 2 1 0.25 2.84 3.26e+ 0 -0.423 -0.225 3.85 -1.01 -1.45 3.22e+ 0 -0.379
#> 3 1 0.57 6.57 5.83e+ 0 0.740 0.297 6.78 -0.215 -0.309 5.77e+ 0 0.795
#> # … with 129 more rows, and 9 more variables: CWRES <dbl>, eta.ka <dbl>,
#> # eta.cl <dbl>, eta.v <dbl>, ka <dbl>, cl <dbl>, v <dbl>, tad <dbl>,
#> # dosenum <dbl>We can alternatively express the same model by ordinary differential equations (ODEs):
one.compartment <- function() {
ini({
tka <- 0.45 # Log Ka
tcl <- 1 # Log Cl
tv <- 3.45 # Log V
eta.ka ~ 0.6
eta.cl ~ 0.3
eta.v ~ 0.1
add.sd <- 0.7
})
model({
ka <- exp(tka + eta.ka)
cl <- exp(tcl + eta.cl)
v <- exp(tv + eta.v)
d/dt(depot) = -ka * depot
d/dt(center) = ka * depot - cl / v * center
cp = center / v
cp ~ add(add.sd)
})
}We can try the Stochastic Approximation EM (SAEM) method to this model:
fit2 <- nlmixr(one.compartment, theo_sd, list(print=0), est="saem")
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
print(fit2)
#> ── nlmixr SAEM(ODE); OBJF not calculated fit ───────────────────────────────────
#>
#> Gaussian/Laplacian Likelihoods: AIC() or $objf etc.
#> FOCEi CWRES & Likelihoods: addCwres()
#>
#> ── Time (sec $time): ───────────────────────────────────────────────────────────
#>
#> saem setup table covariance other
#> elapsed 5.554 1.664152 0.012 0.011 0.551848
#>
#> ── Population Parameters ($parFixed or $parFixedDf): ───────────────────────────
#>
#> Parameter Est. SE %RSE Back-transformed(95%CI) BSV(CV%) Shrink(SD)%
#> tka Log Ka 0.452 0.197 43.5 1.57 (1.07, 2.31) 72.0 0.361%
#> tcl Log Cl 1.02 0.0836 8.22 2.77 (2.35, 3.26) 27.0 3.37%
#> tv Log V 3.45 0.0469 1.36 31.5 (28.7, 34.5) 14.0 9.96%
#> add.sd 0.692 0.692
#>
#> Covariance Type ($covMethod): linFim
#> Fixed parameter correlations in $cor
#> No correlations in between subject variability (BSV) matrix
#> Full BSV covariance ($omega) or correlation ($omegaR; diagonals=SDs)
#> Distribution stats (mean/skewness/kurtosis/p-value) available in $shrink
#>
#> ── Fit Data (object is a modified tibble): ─────────────────────────────────────
#> # A tibble: 132 × 19
#> ID TIME DV PRED RES IPRED IRES IWRES eta.ka eta.cl eta.v cp
#> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 0 0.74 0 0.74 0 0.74 1.07 0.104 -0.487 -0.0801 0
#> 2 1 0.25 2.84 3.26 -0.425 3.86 -1.02 -1.48 0.104 -0.487 -0.0801 3.86
#> 3 1 0.57 6.57 5.85 0.724 6.81 -0.235 -0.340 0.104 -0.487 -0.0801 6.81
#> # … with 129 more rows, and 7 more variables: depot <dbl>, center <dbl>,
#> # ka <dbl>, cl <dbl>, v <dbl>, tad <dbl>, dosenum <dbl>And if we wanted to, we could even apply the traditional R method nlme method to this model:
fitN <- nlmixr(one.compartment, theo_sd, list(pnlsTol=0.5), est="nlme")
#>
#> **Iteration 1
#> LME step: Loglik: -200.3342, nlminb iterations: 1
#> reStruct parameters:
#> ID1 ID2 ID3
#> 1.271715 1.182324 2.187380
#> Beginning PNLS step: .. completed fit_nlme() step.
#> PNLS step: RSS = 65.5344
#> fixed effects: 0.4839788 0.9956147 3.475748
#> iterations: 5
#> Convergence crit. (must all become <= tolerance = 1e-05):
#> fixed reStruct
#> 0.07020724 12.68355662
#>
#> **Iteration 2
#> LME step: Loglik: -178.6729, nlminb iterations: 1
#> reStruct parameters:
#> ID1 ID2 ID3
#> 0.09293748 0.91437047 1.56871691
#> Beginning PNLS step: .. completed fit_nlme() step.
#> PNLS step: RSS = 65.53441
#> fixed effects: 0.4839788 0.9956147 3.475748
#> iterations: 1
#> Convergence crit. (must all become <= tolerance = 1e-05):
#> fixed reStruct
#> 0.000000e+00 3.717616e-06
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
print(fitN)
#> ── nlmixr nlme by maximum likelihood (ODE; μ-ref & covs) fit ───────────────────
#>
#> OBJF AIC BIC Log-likelihood Condition Number
#> FOCEi 122.1948 378.7946 398.9742 -182.3973 16.04255
#> nlme 114.7459 371.3457 391.5253 -178.6729 16.04255
#>
#> ── Time (sec $time): ───────────────────────────────────────────────────────────
#>
#> nlme setup table cwres other
#> elapsed -0.734 3.353581 0.017 3.386 0.218419
#>
#> ── Population Parameters ($parFixed or $parFixedDf): ───────────────────────────
#>
#> Parameter Est. SE %RSE Back-transformed(95%CI) BSV(CV%) Shrink(SD)%
#> tka Log Ka 0.484 0.187 38.7 1.62 (1.12, 2.34) 67.6 -0.748%
#> tcl Log Cl 0.996 0.0865 8.68 2.71 (2.28, 3.21) 27.5 7.91%
#> tv Log V 3.48 0.0467 1.34 32.3 (29.5, 35.4) 14.1 -0.0171%
#> add.sd 0.674 0.674
#>
#> Covariance Type ($covMethod): nlme
#> Fixed parameter correlations in $cor
#> No correlations in between subject variability (BSV) matrix
#> Full BSV covariance ($omega) or correlation ($omegaR; diagonals=SDs)
#> Distribution stats (mean/skewness/kurtosis/p-value) available in $shrink
#>
#> ── Fit Data (object is a modified tibble): ─────────────────────────────────────
#> # A tibble: 132 × 22
#> ID TIME DV PRED RES WRES IPRED IRES IWRES CPRED CRES CWRES
#> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 0 0.74 0 0.74 1.10 0 0.74 1.10 0 0.74 1.10
#> 2 1 0.25 2.84 3.26 -0.425 -0.234 3.94 -1.10 -1.63 3.21 -0.367 -0.175
#> 3 1 0.57 6.57 5.81 0.758 0.316 6.87 -0.303 -0.450 5.75 0.823 0.310
#> # … with 129 more rows, and 10 more variables: eta.ka <dbl>, eta.cl <dbl>,
#> # eta.v <dbl>, depot <dbl>, center <dbl>, ka <dbl>, cl <dbl>, v <dbl>,
#> # tad <dbl>, dosenum <dbl>This example delivers a complete model fit as the fit object, including parameter history, a set of fixed effect estimates, and random effects for all included subjects.
Now back to the saem fit; Let’s look at the fit using nlmixr’s built-in diagnostics…
plot(fit)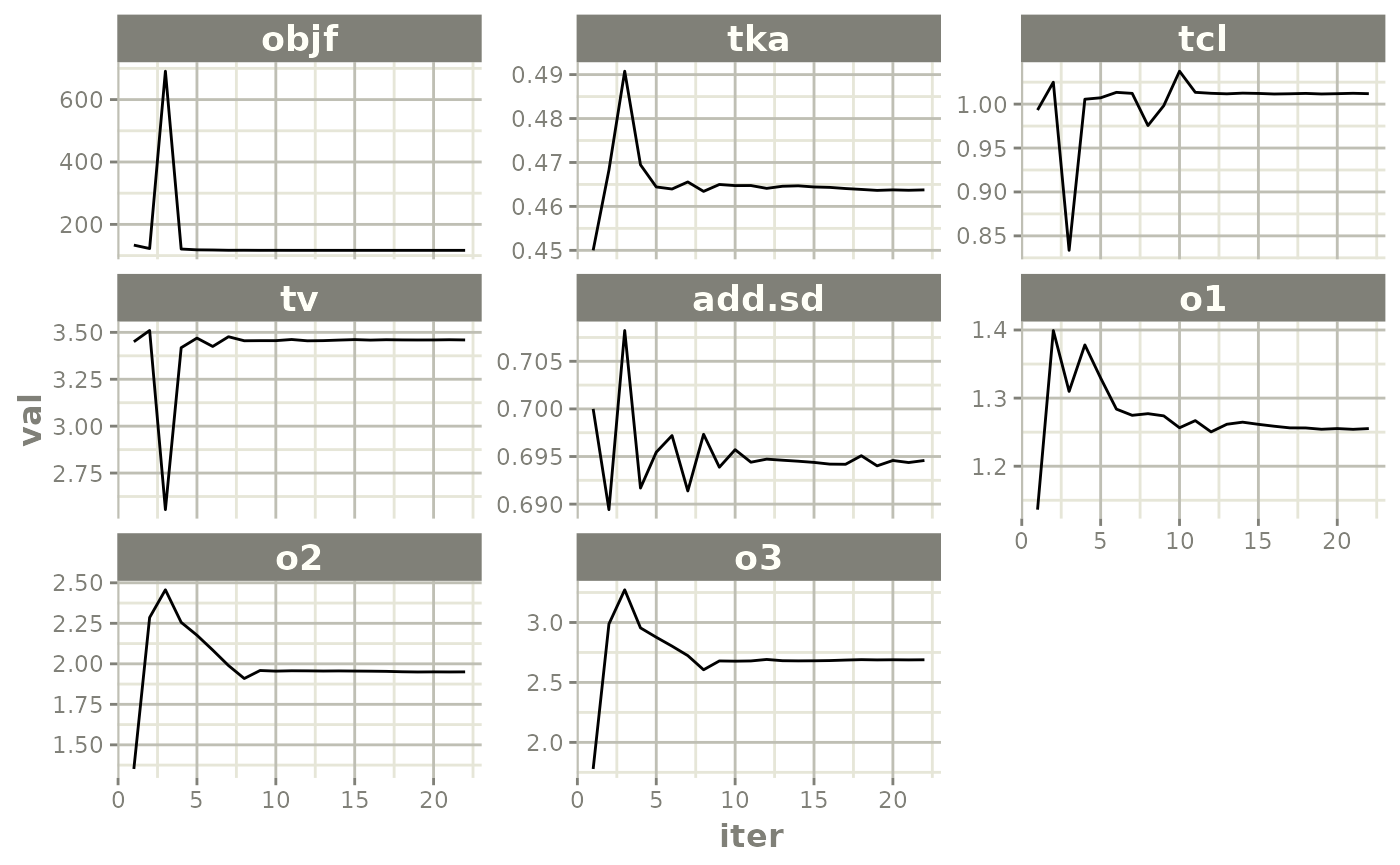
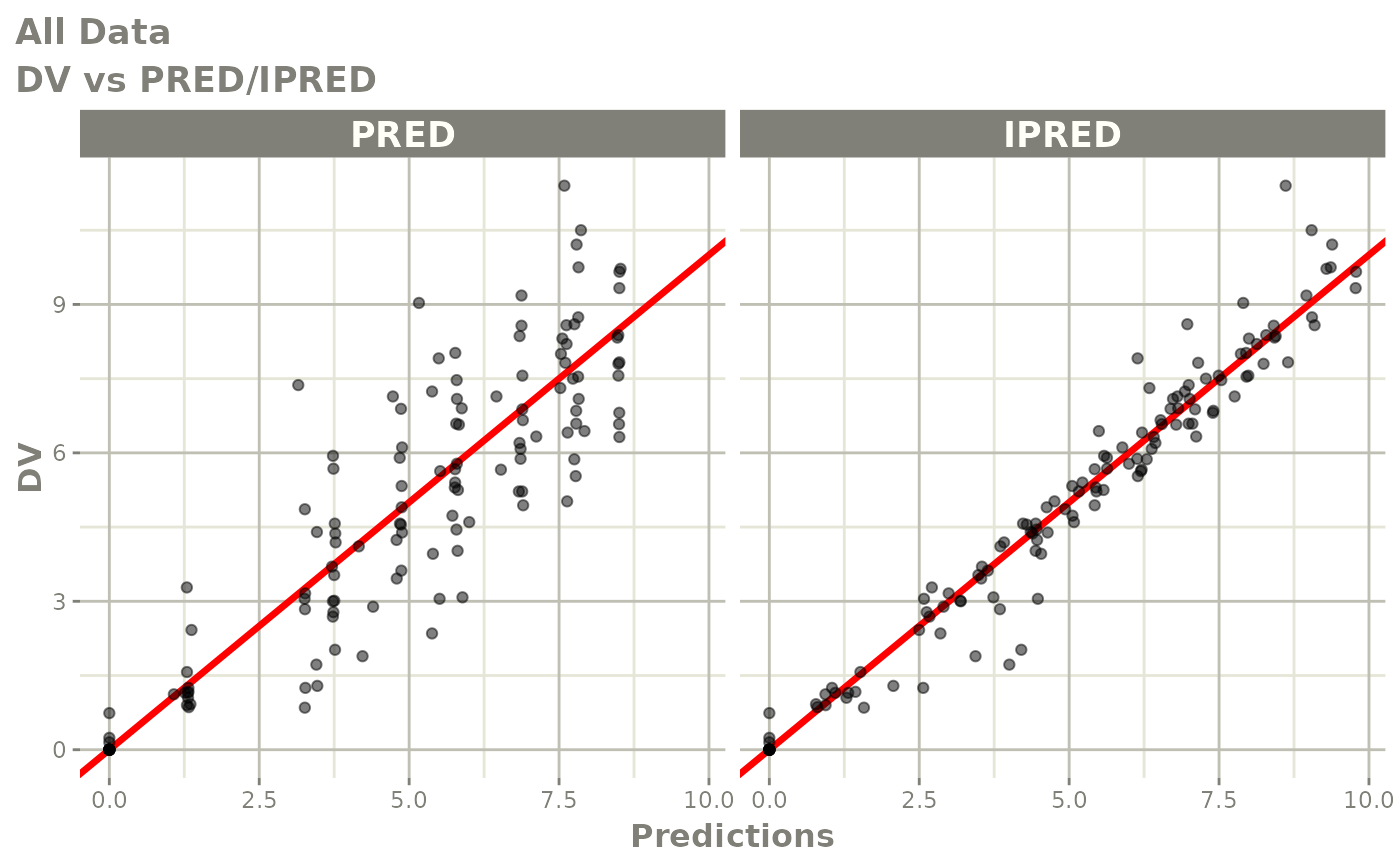
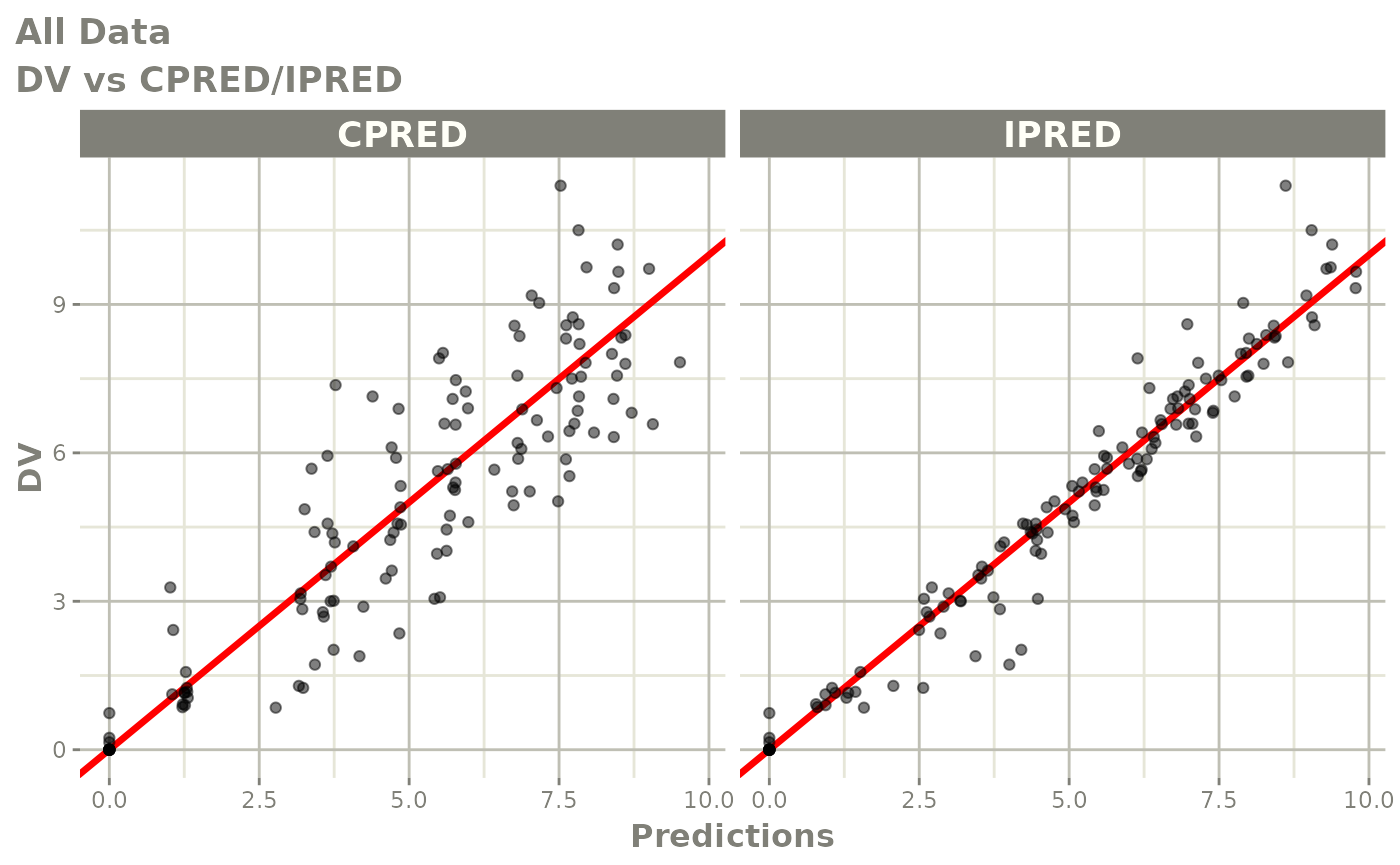
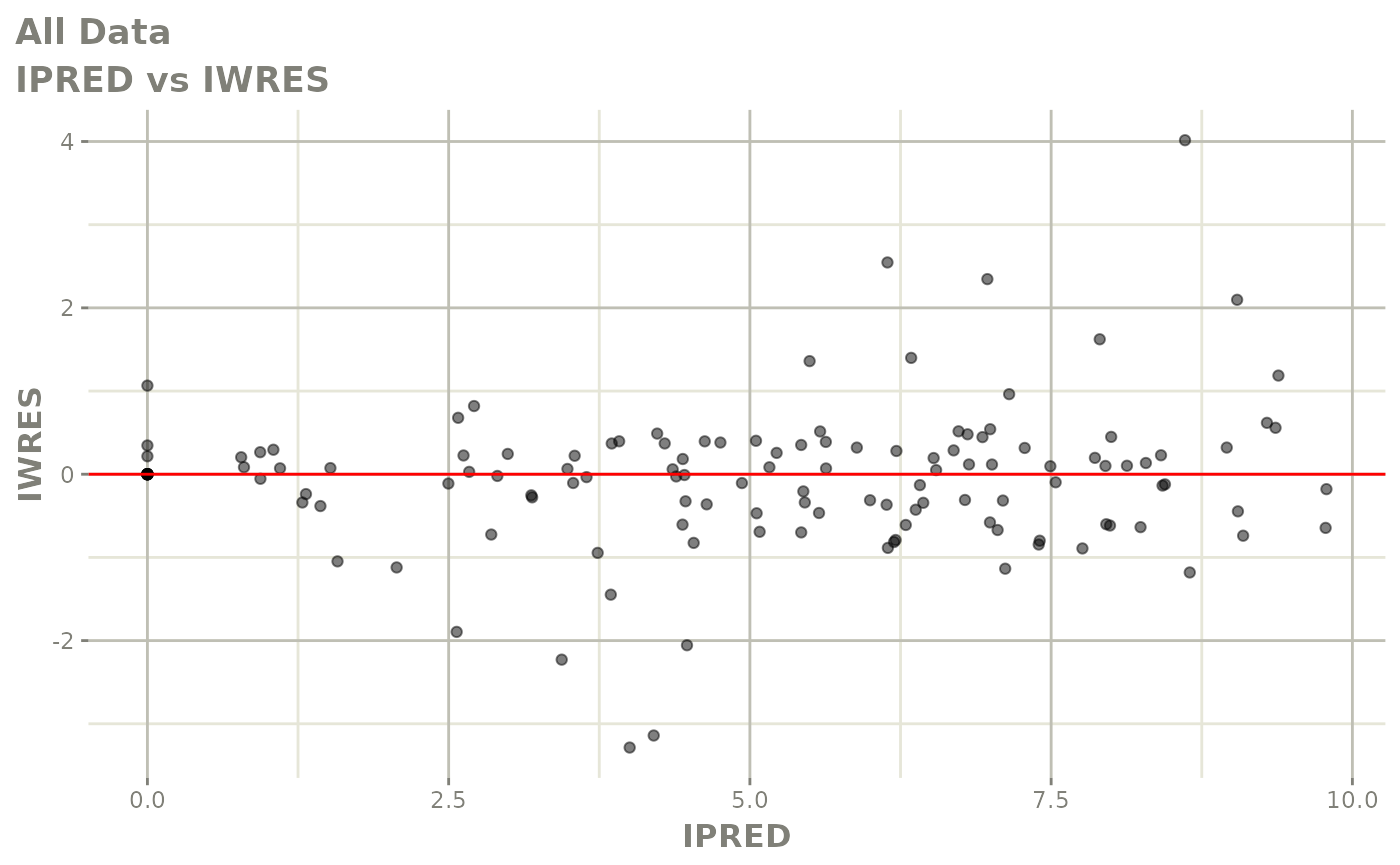
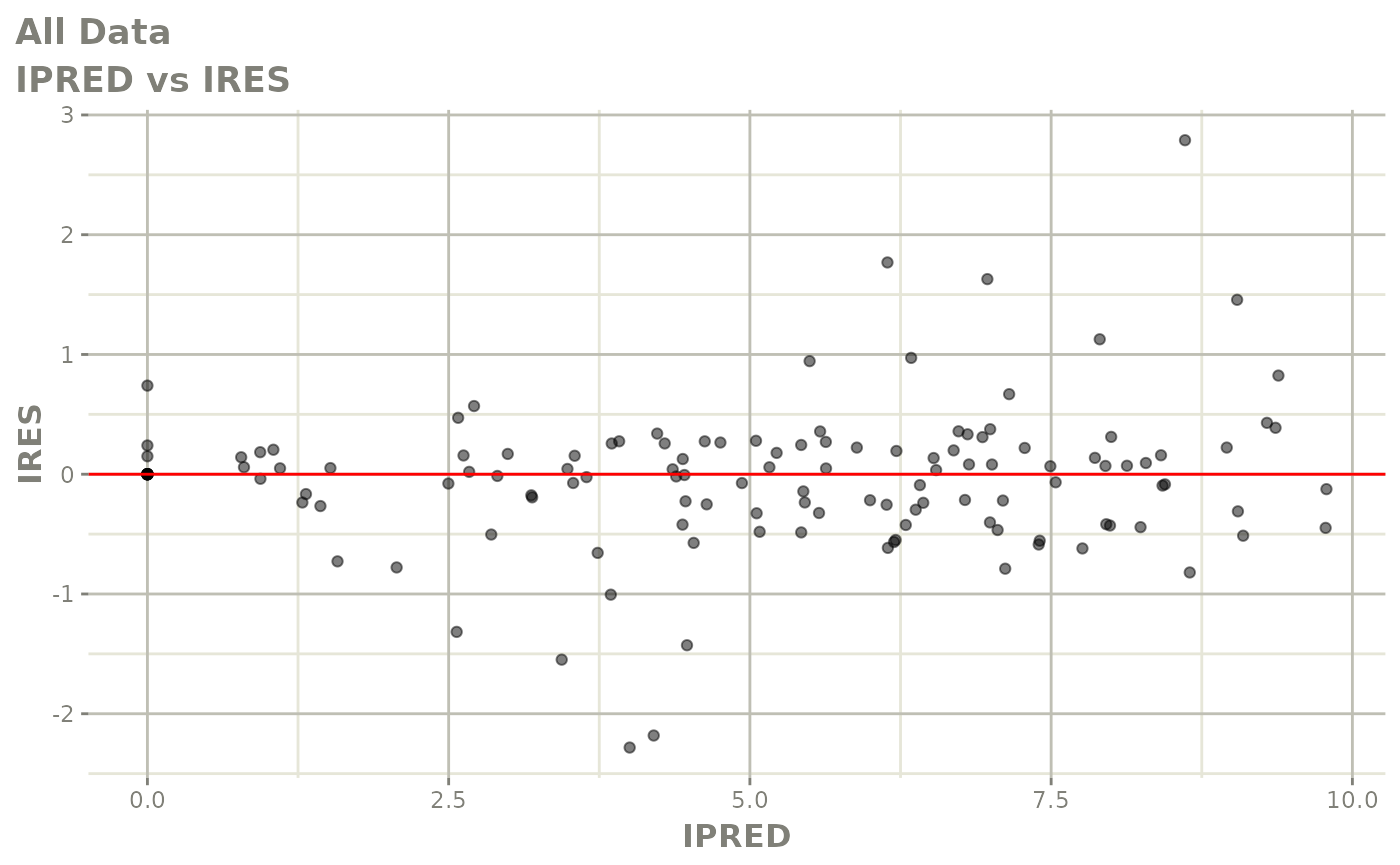
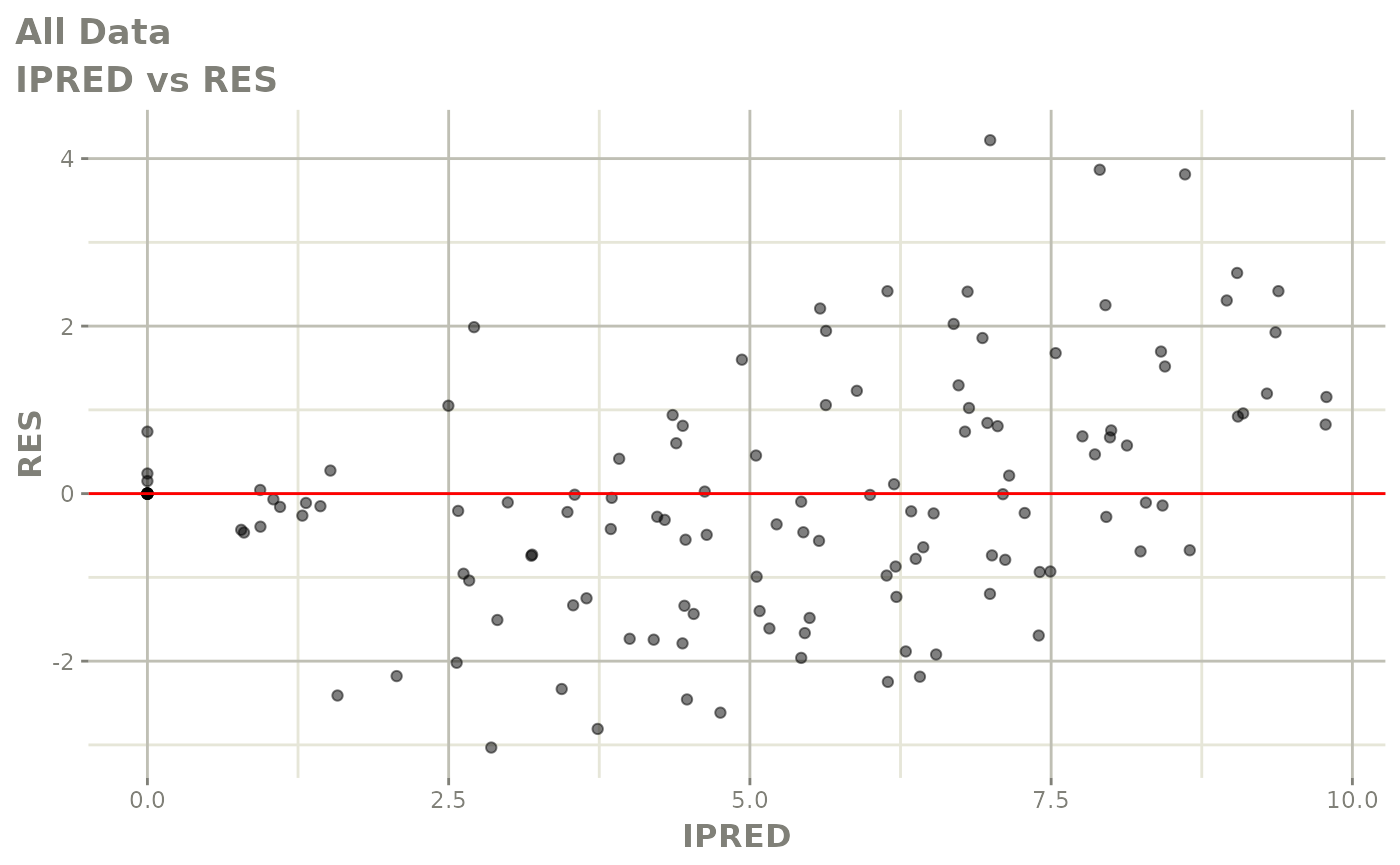
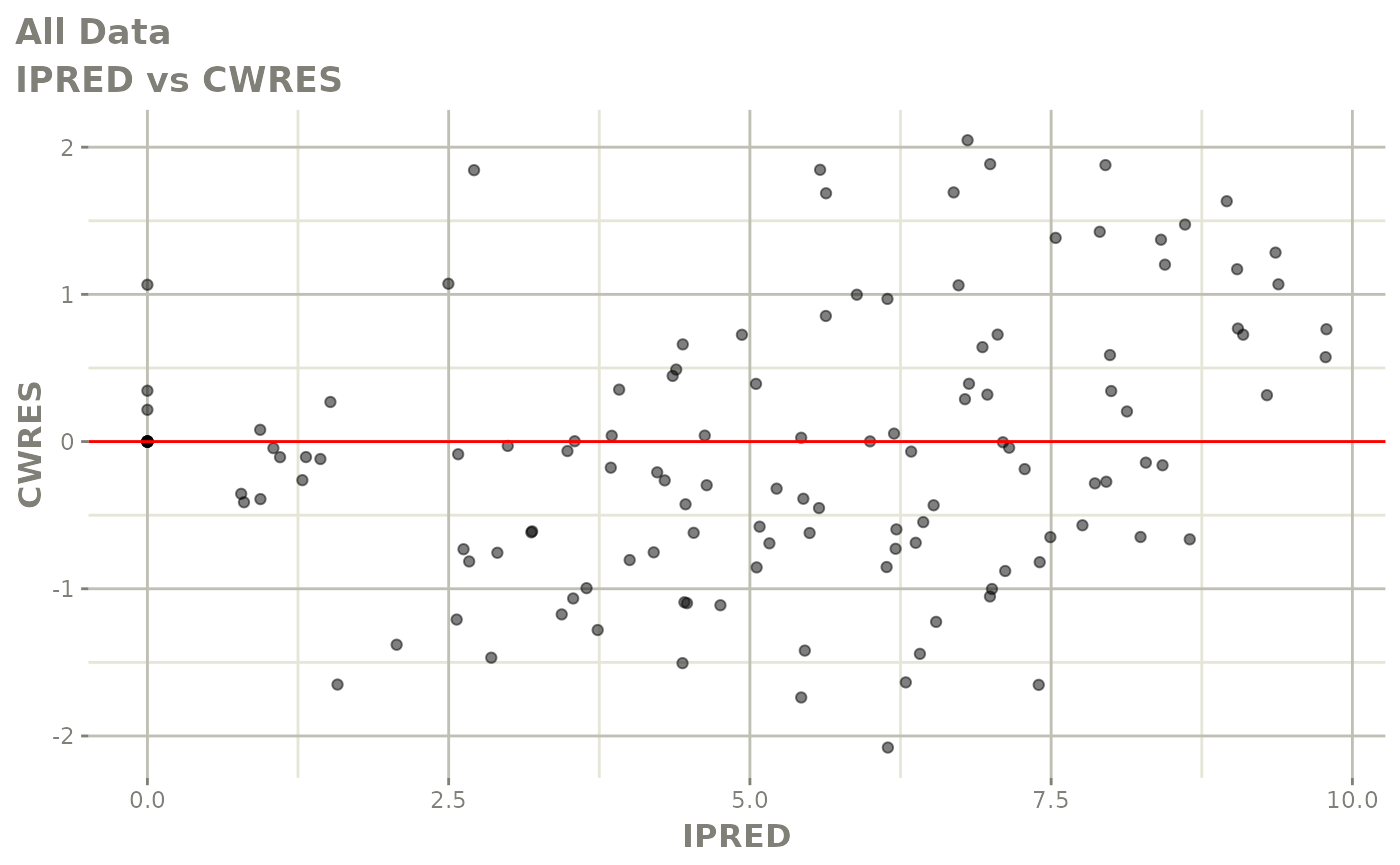
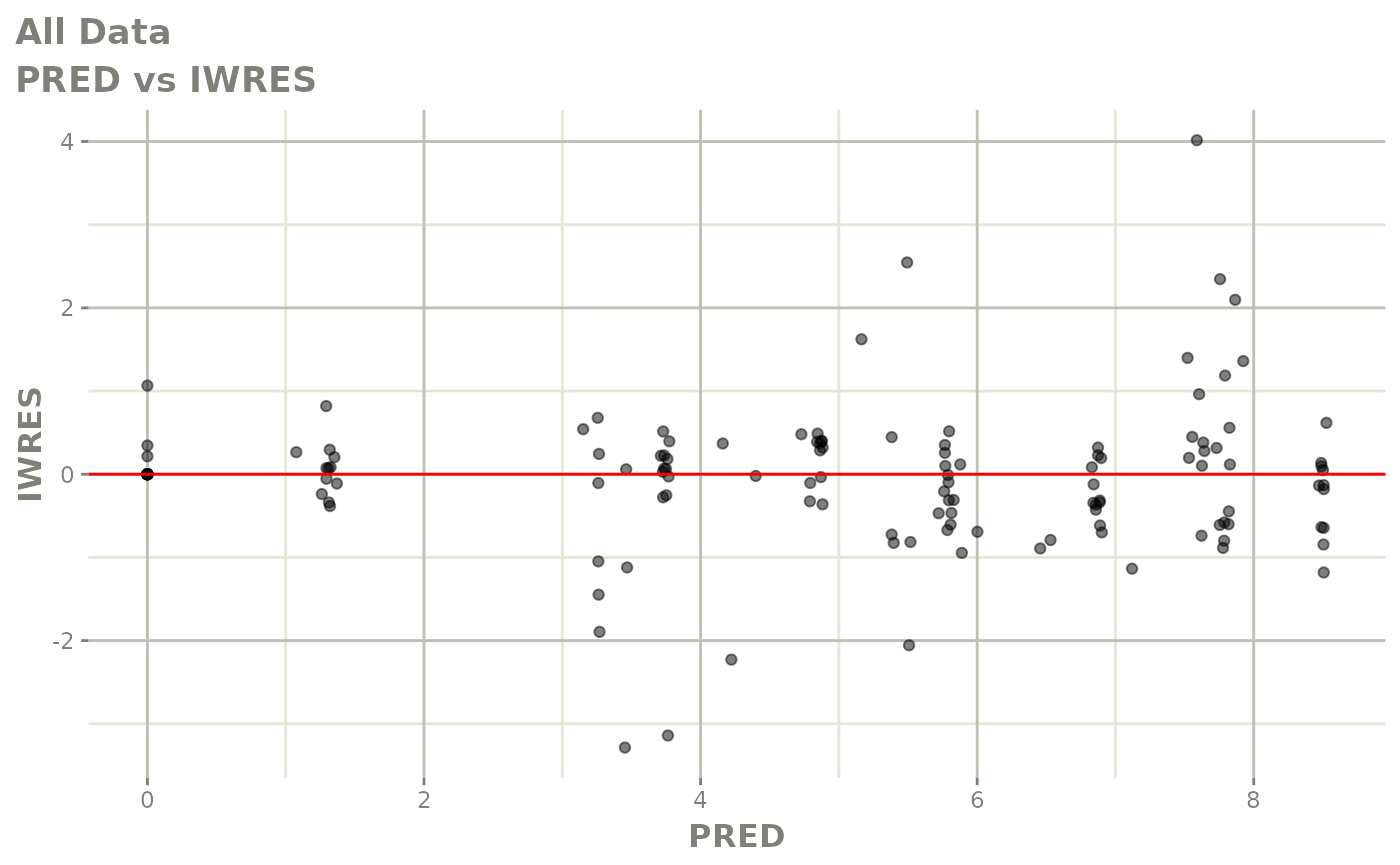
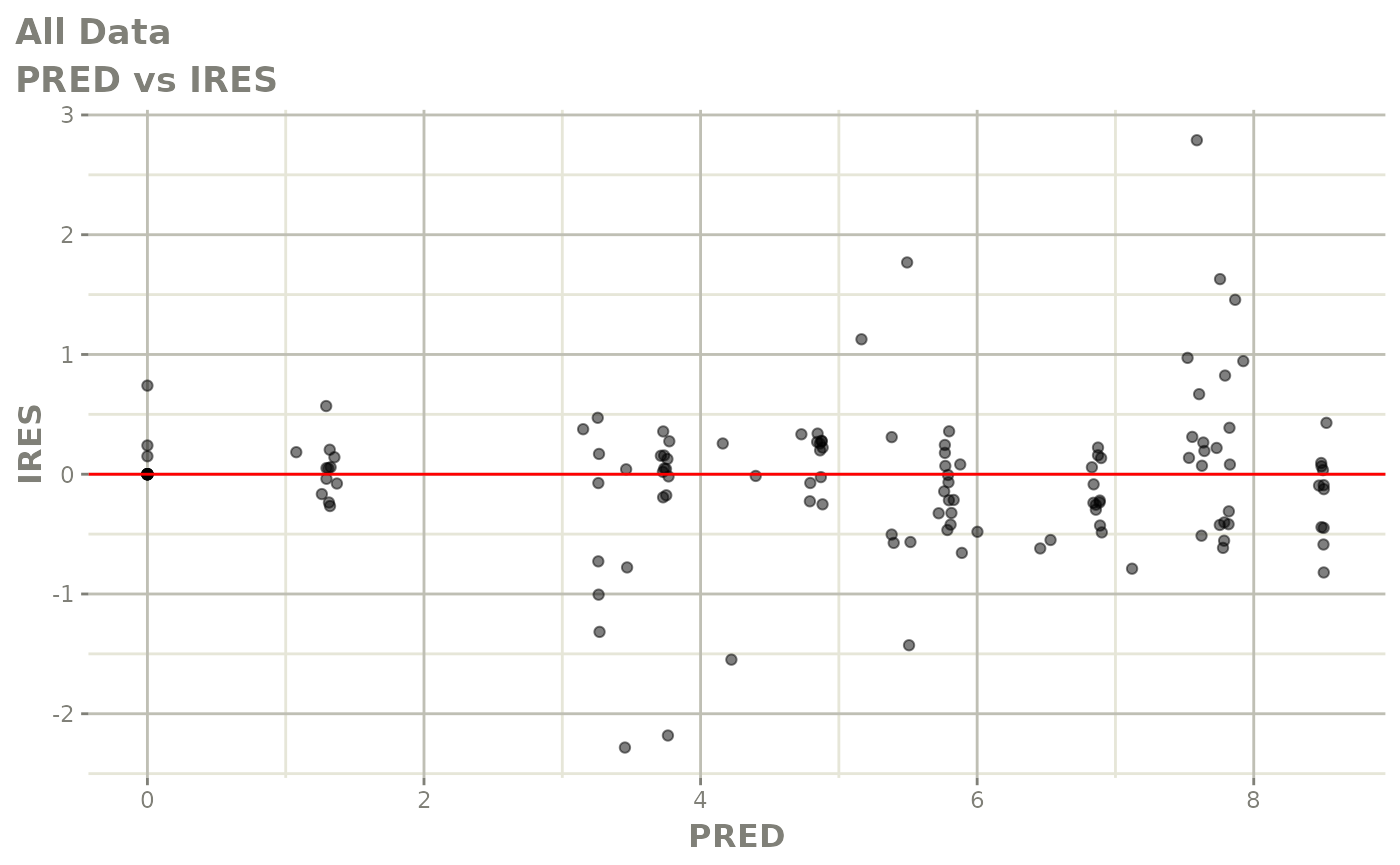
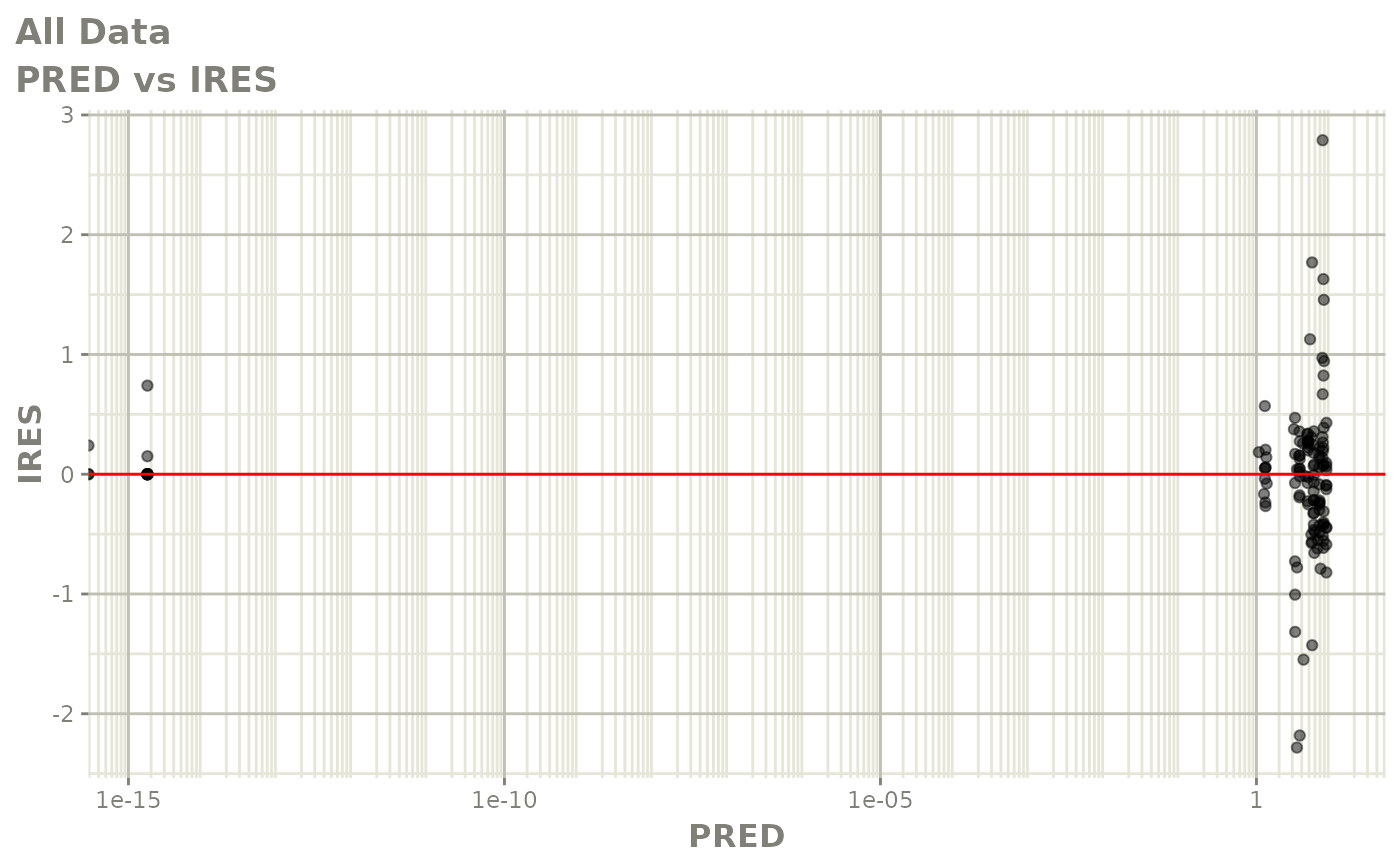
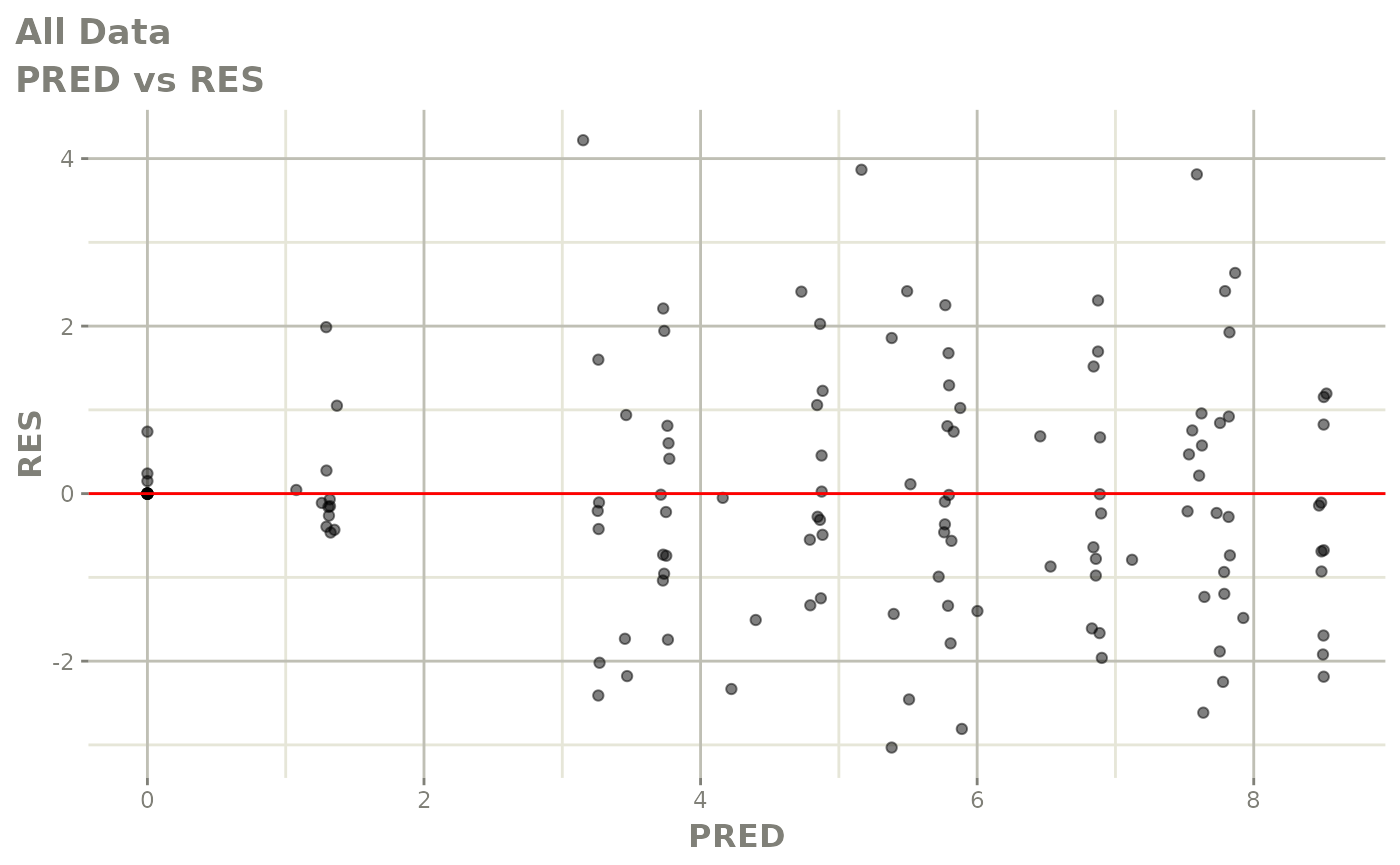
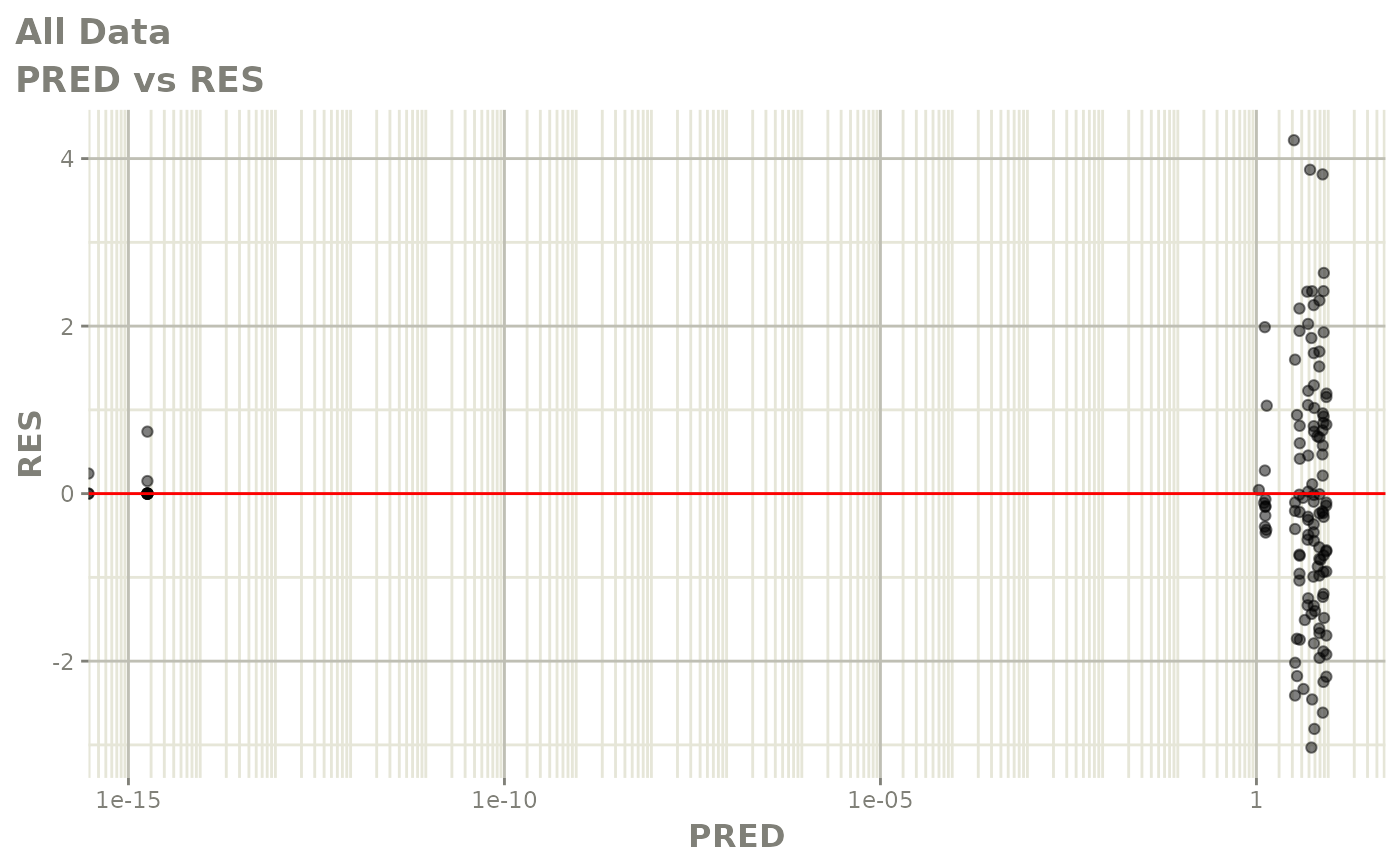
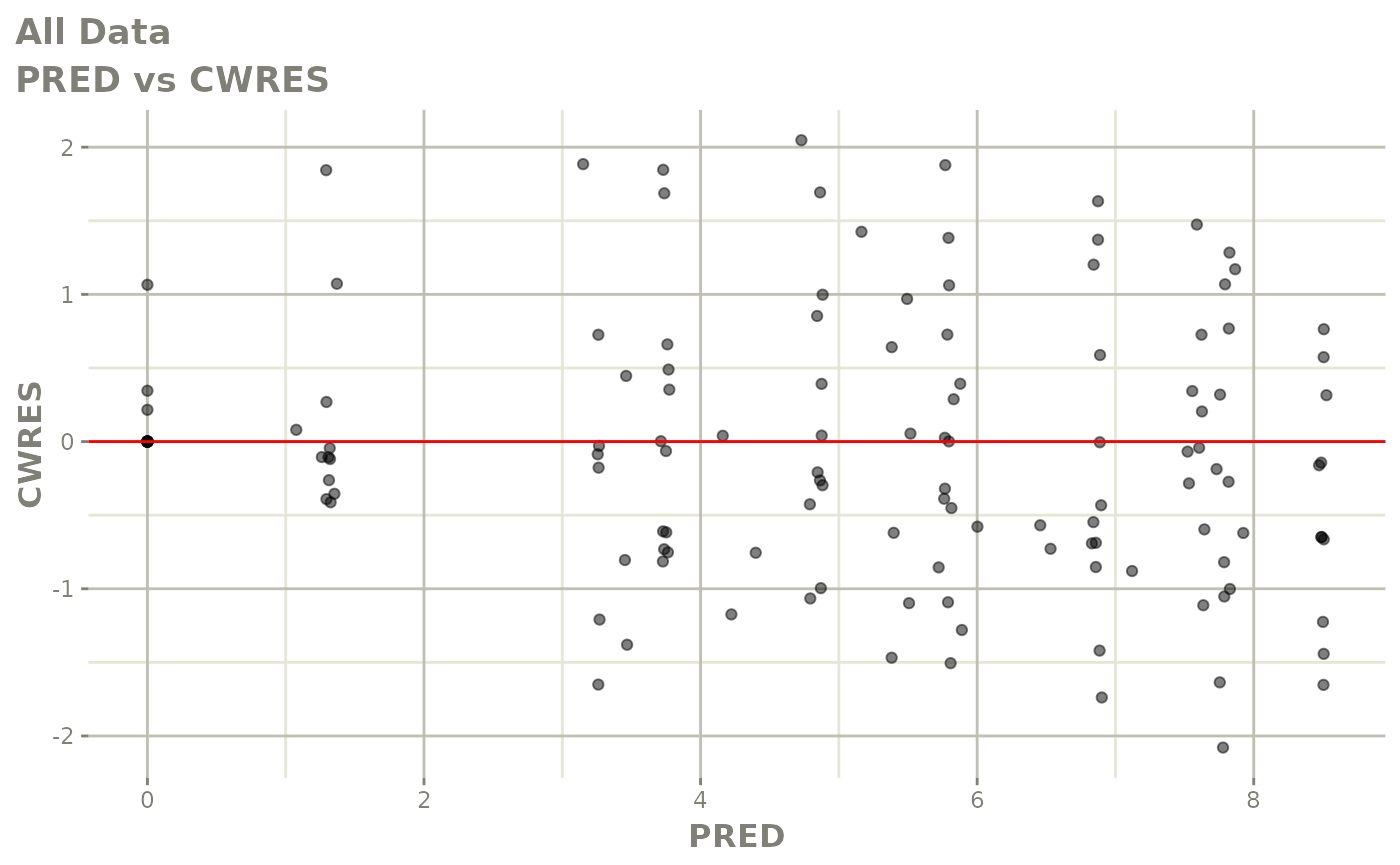
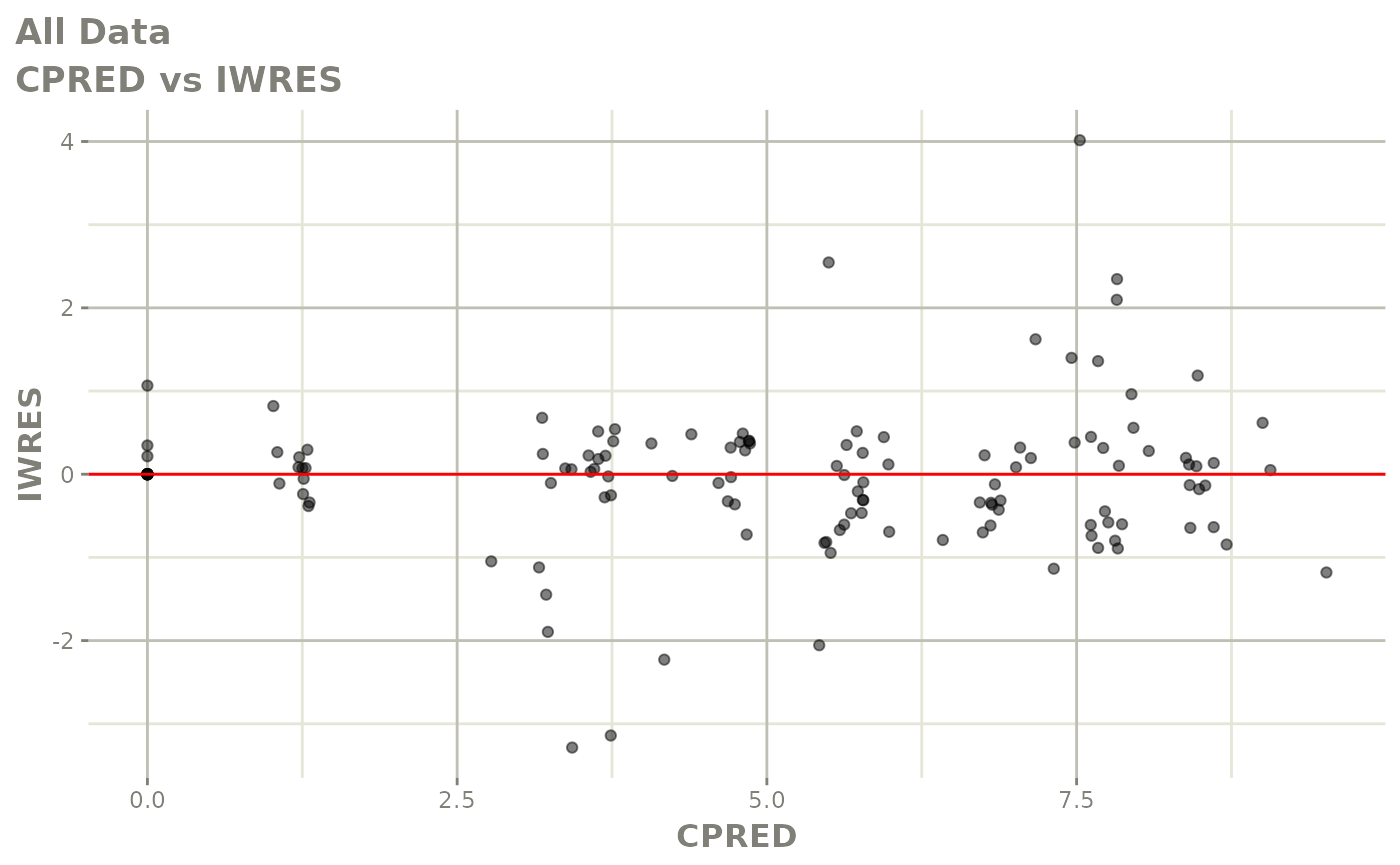
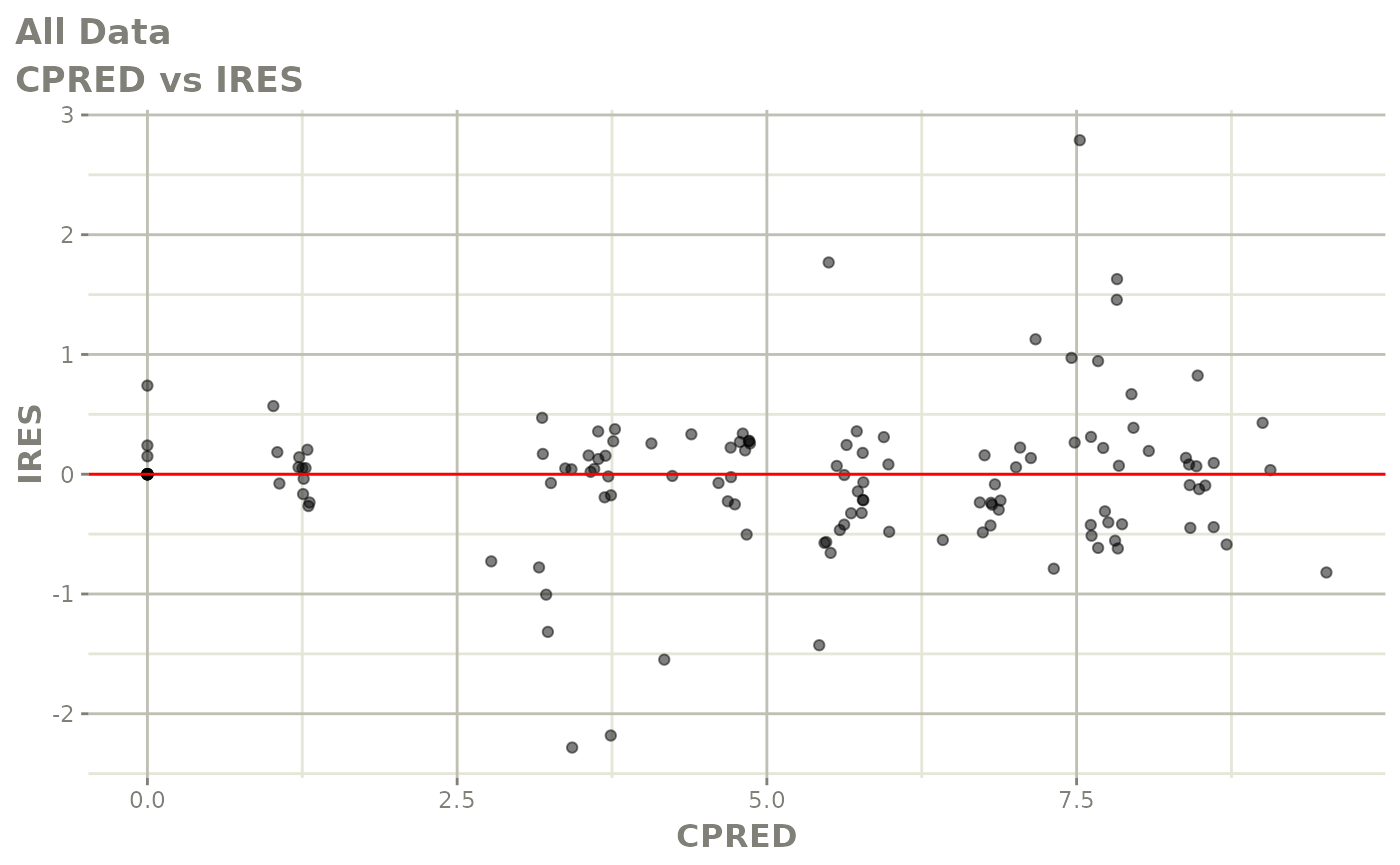
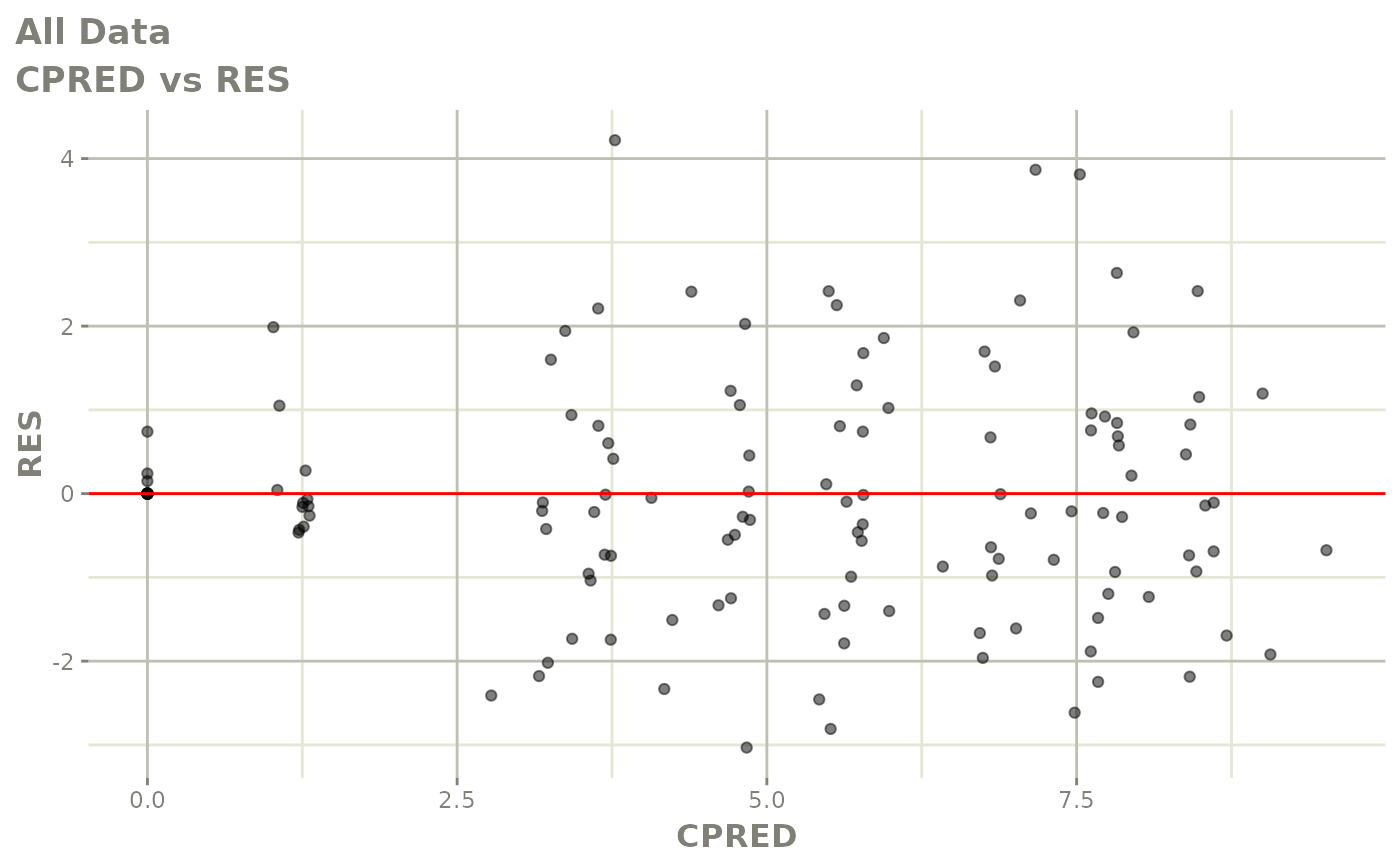
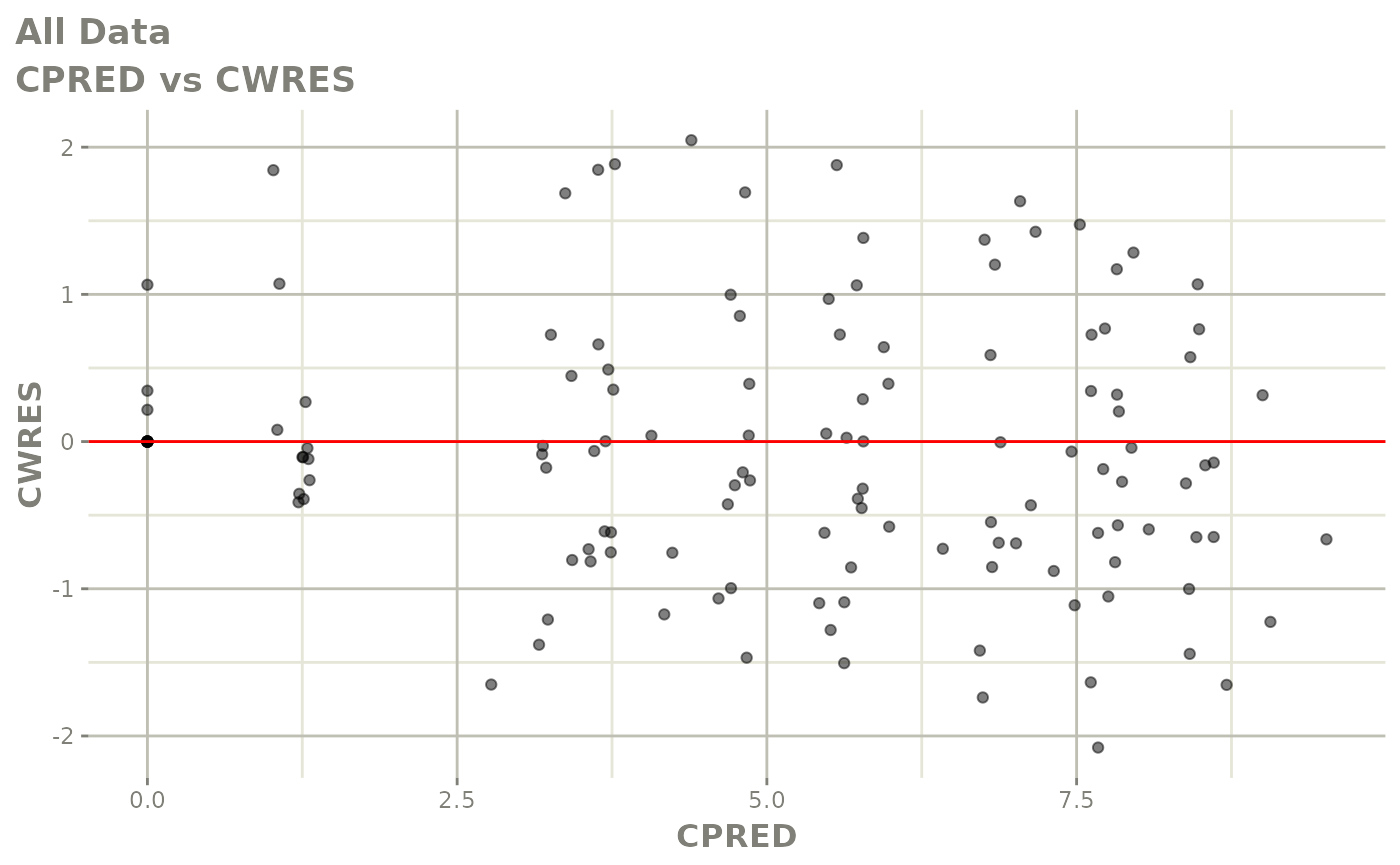
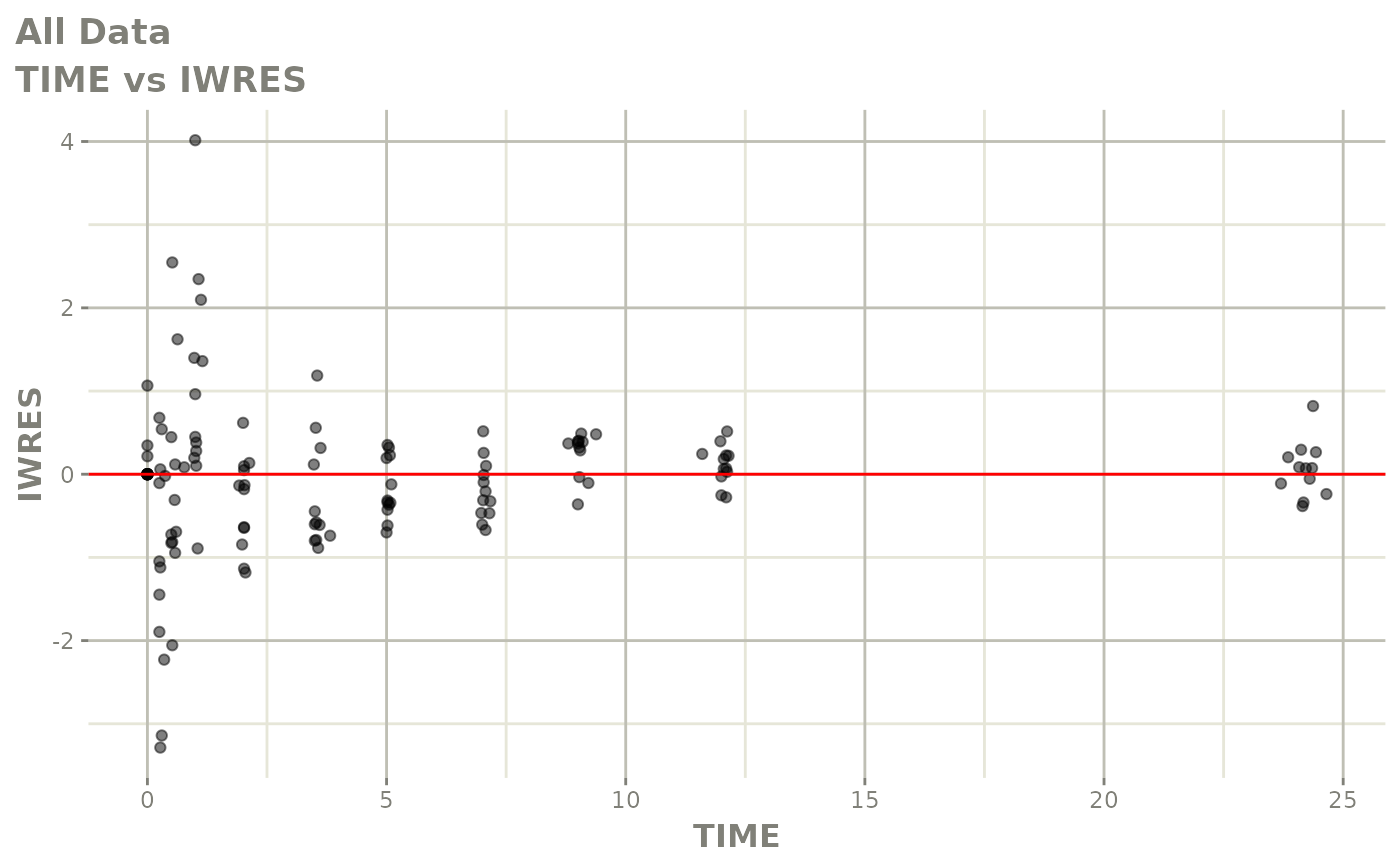
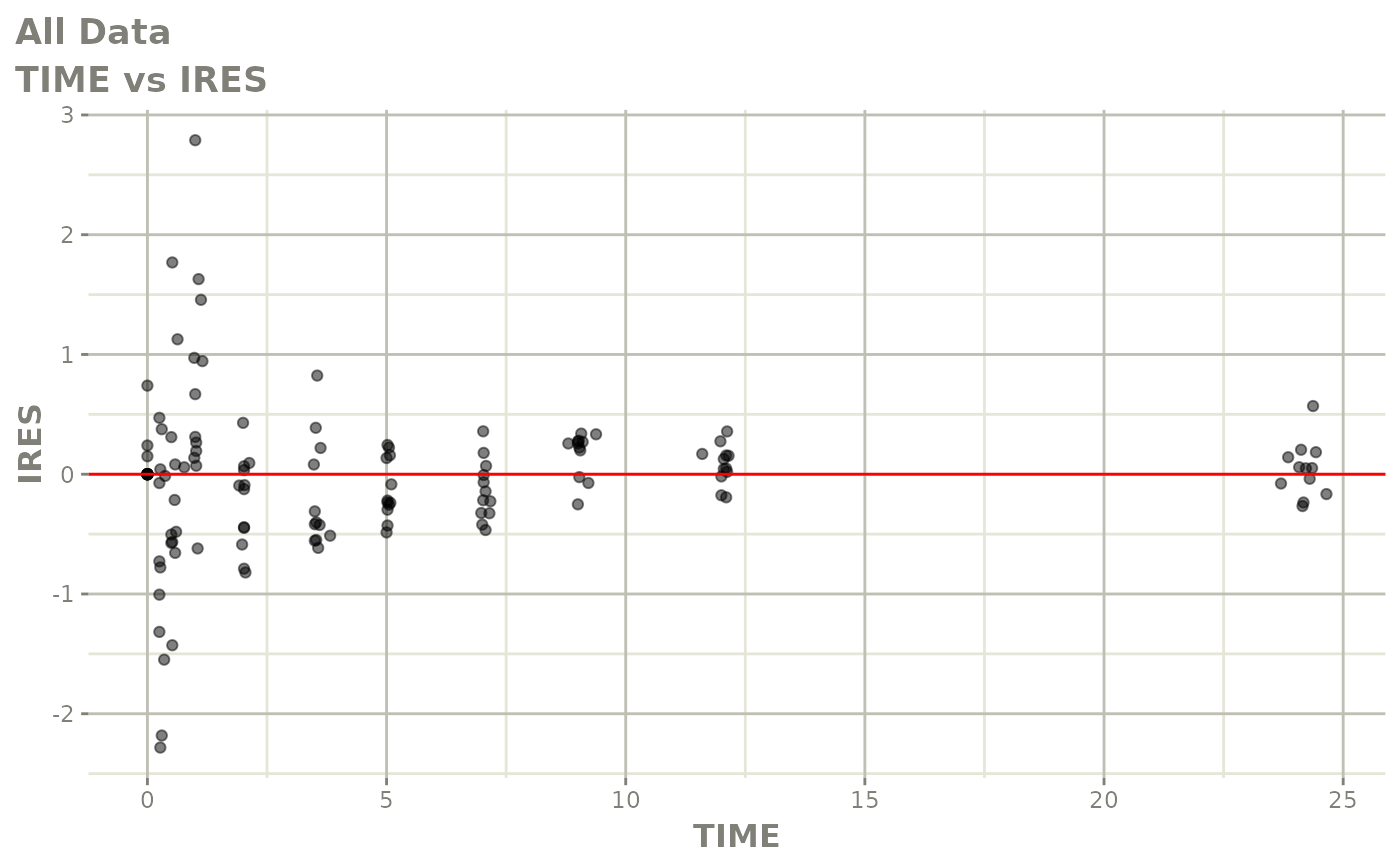
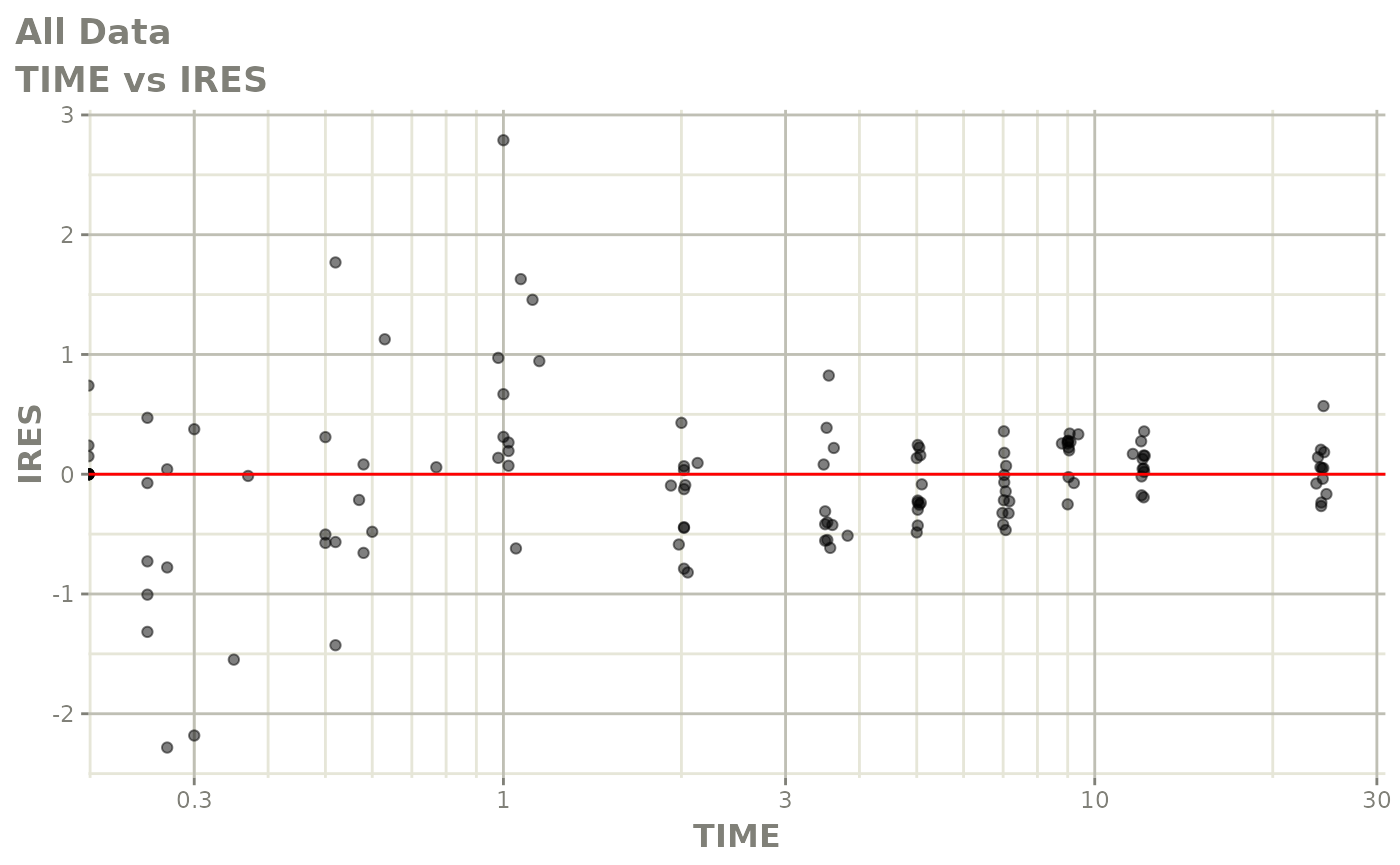
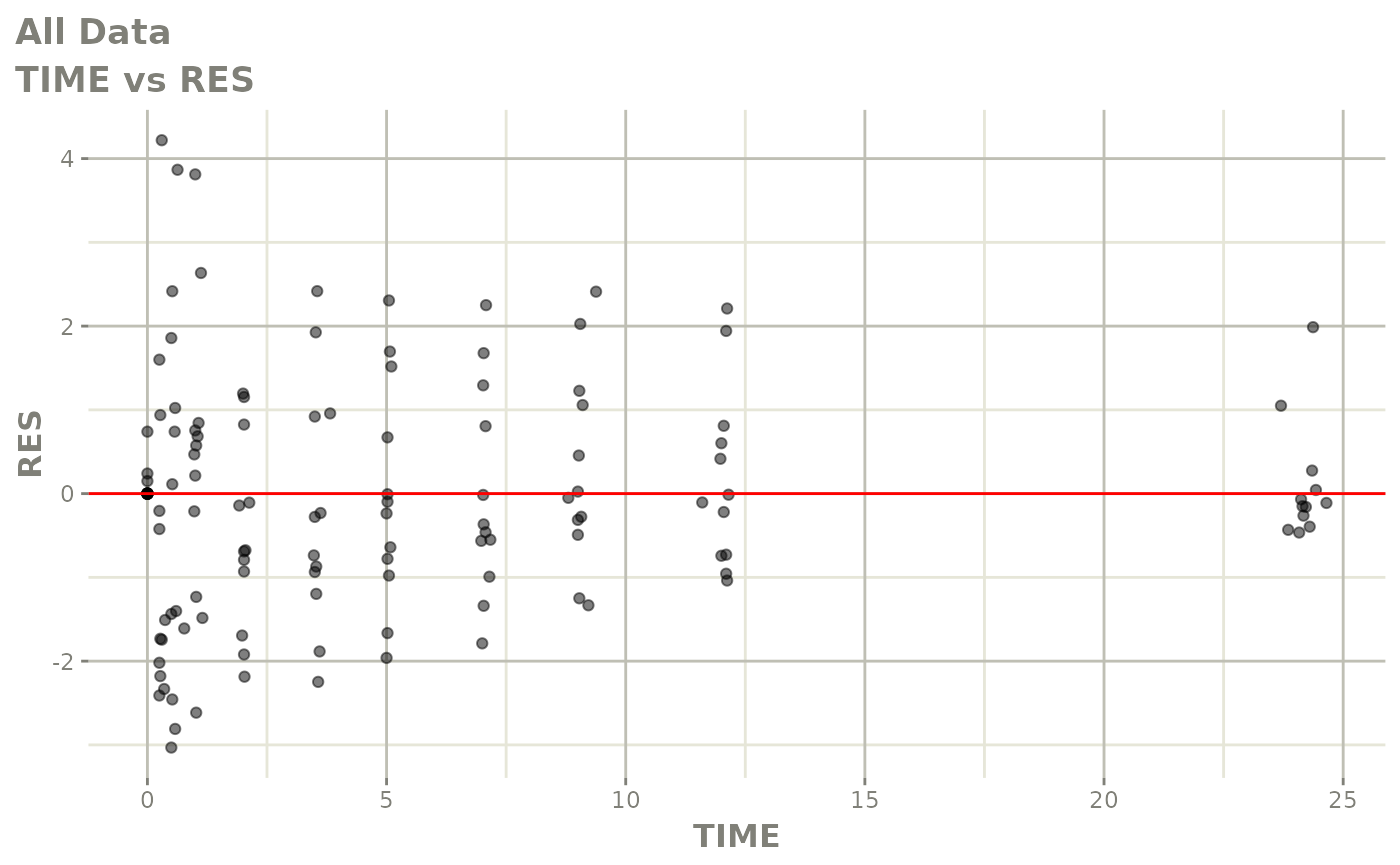
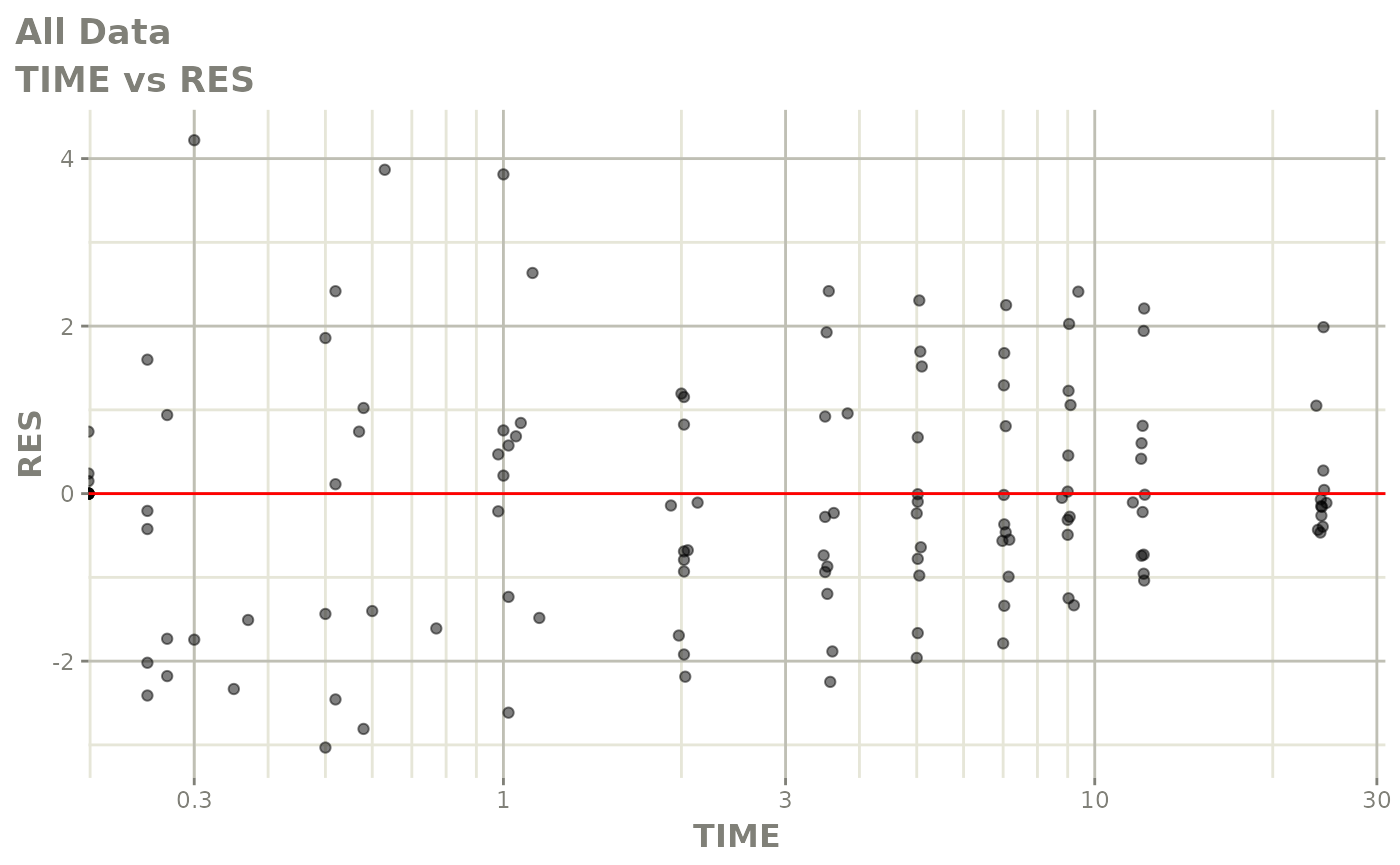
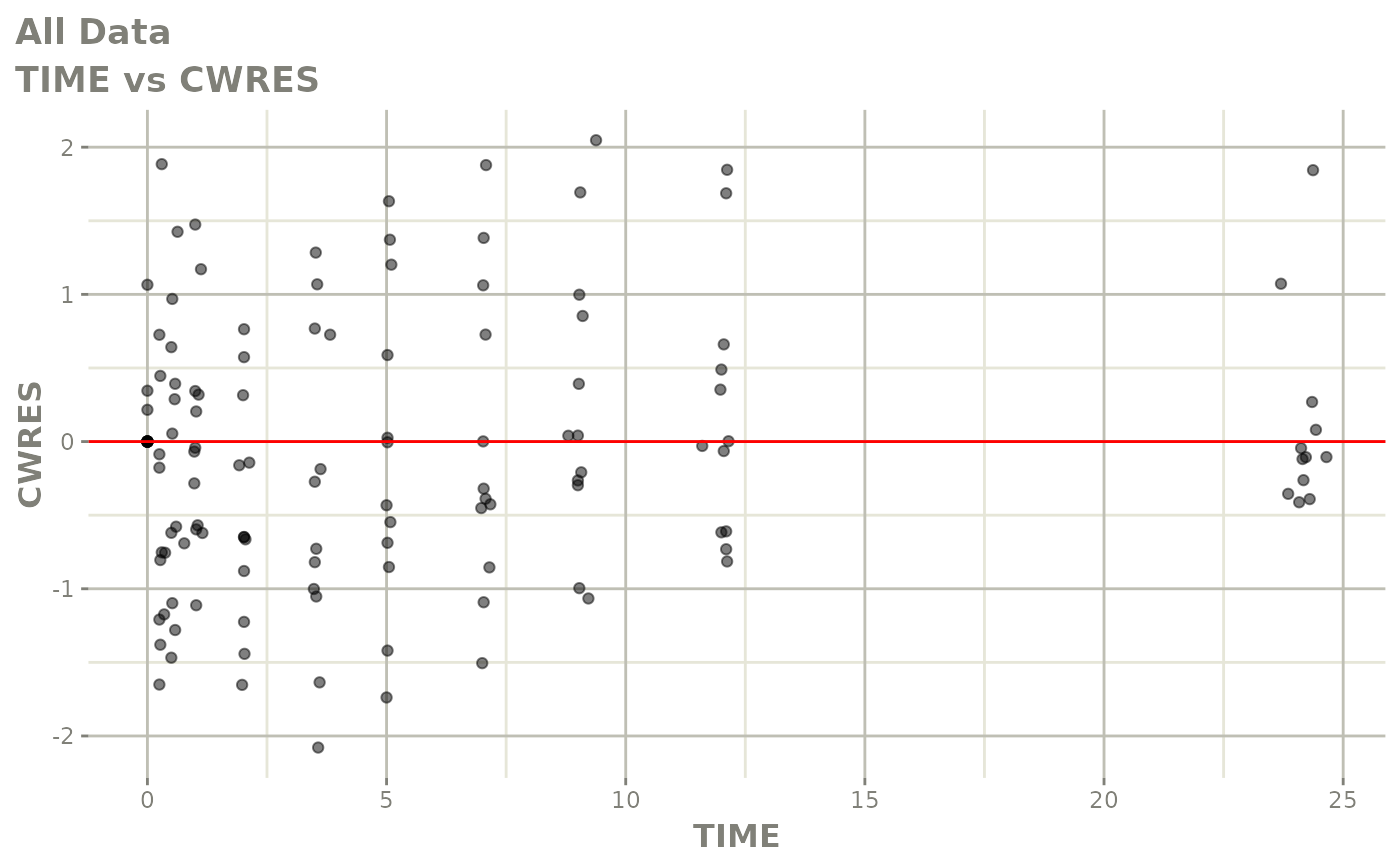
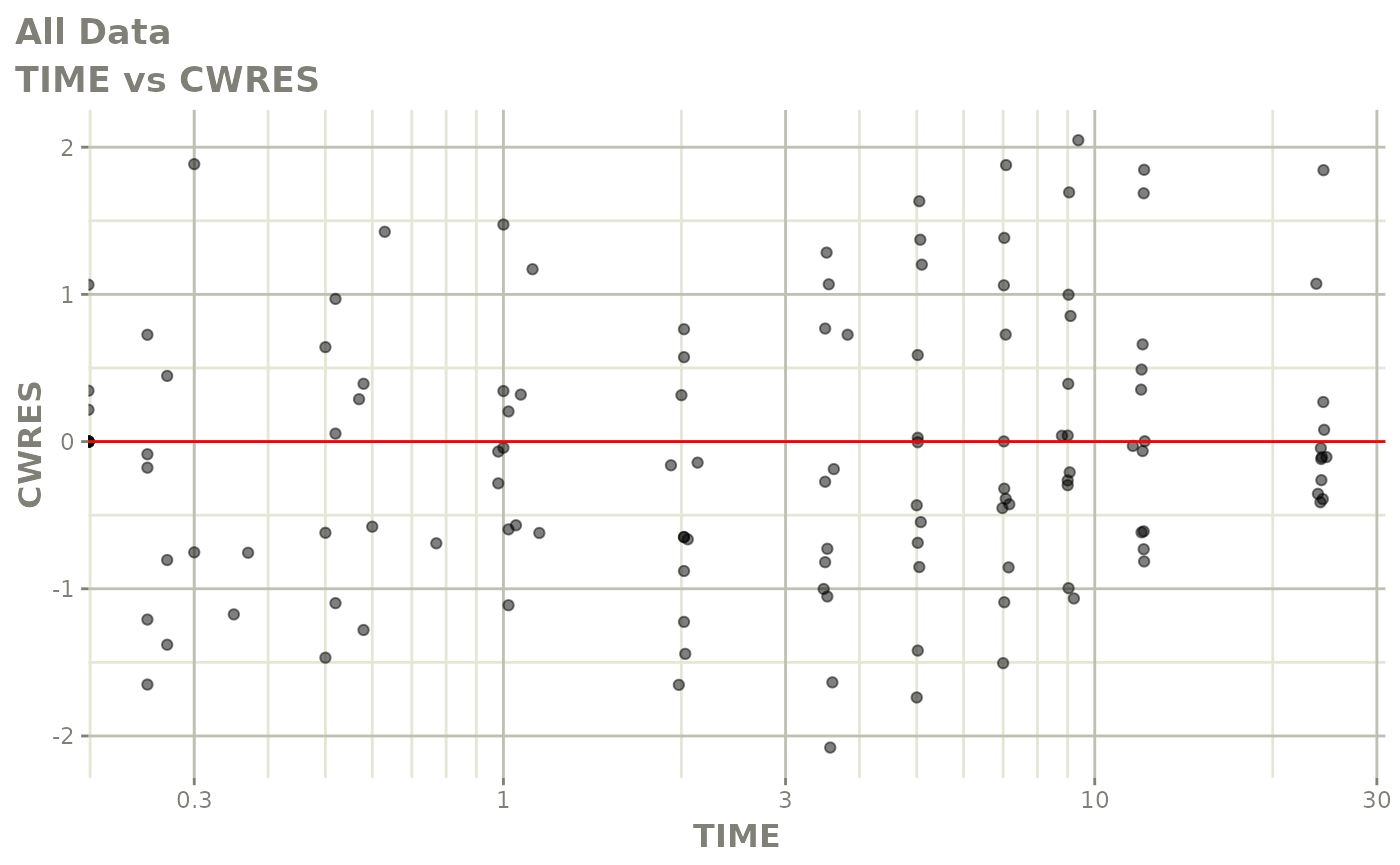
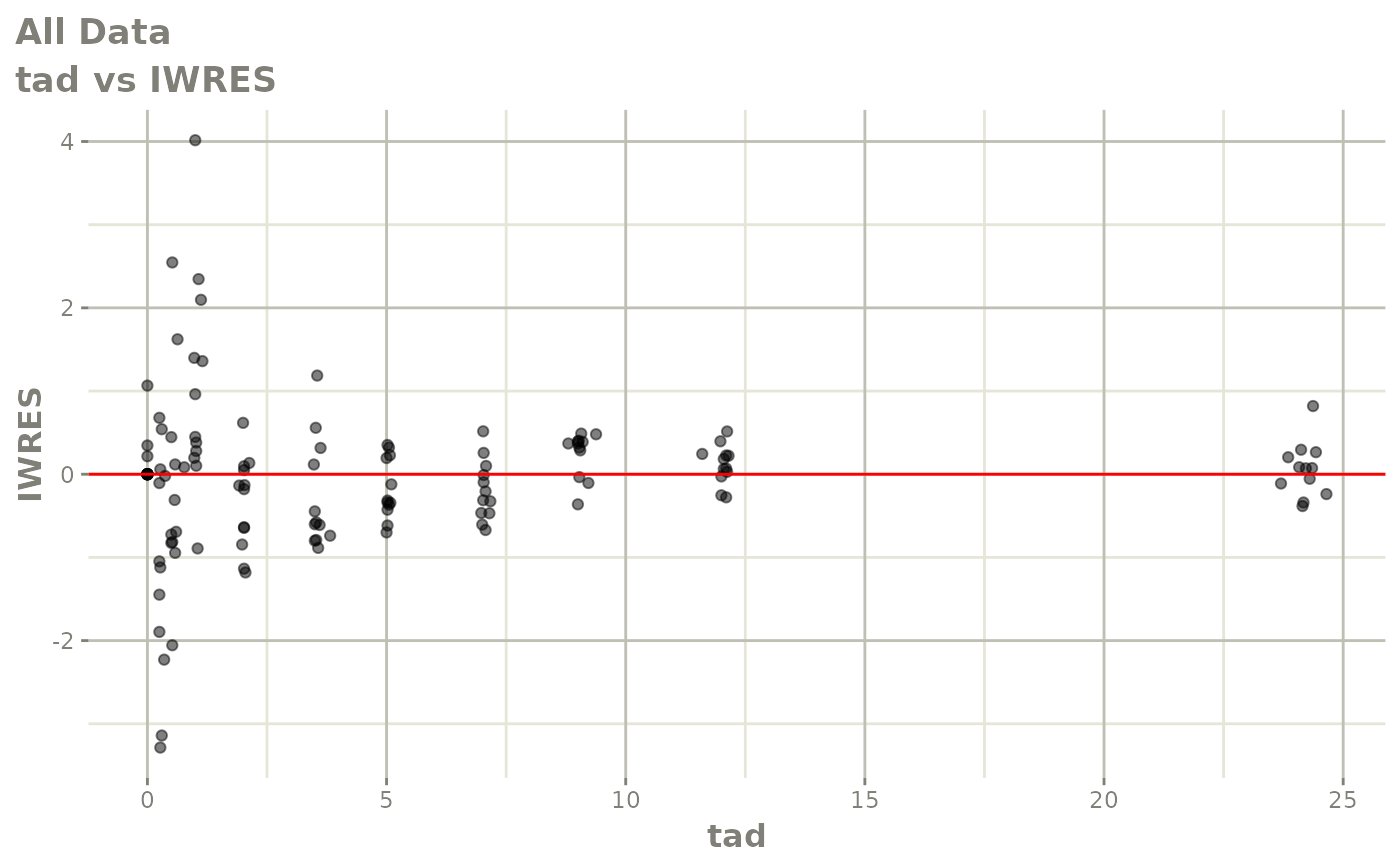
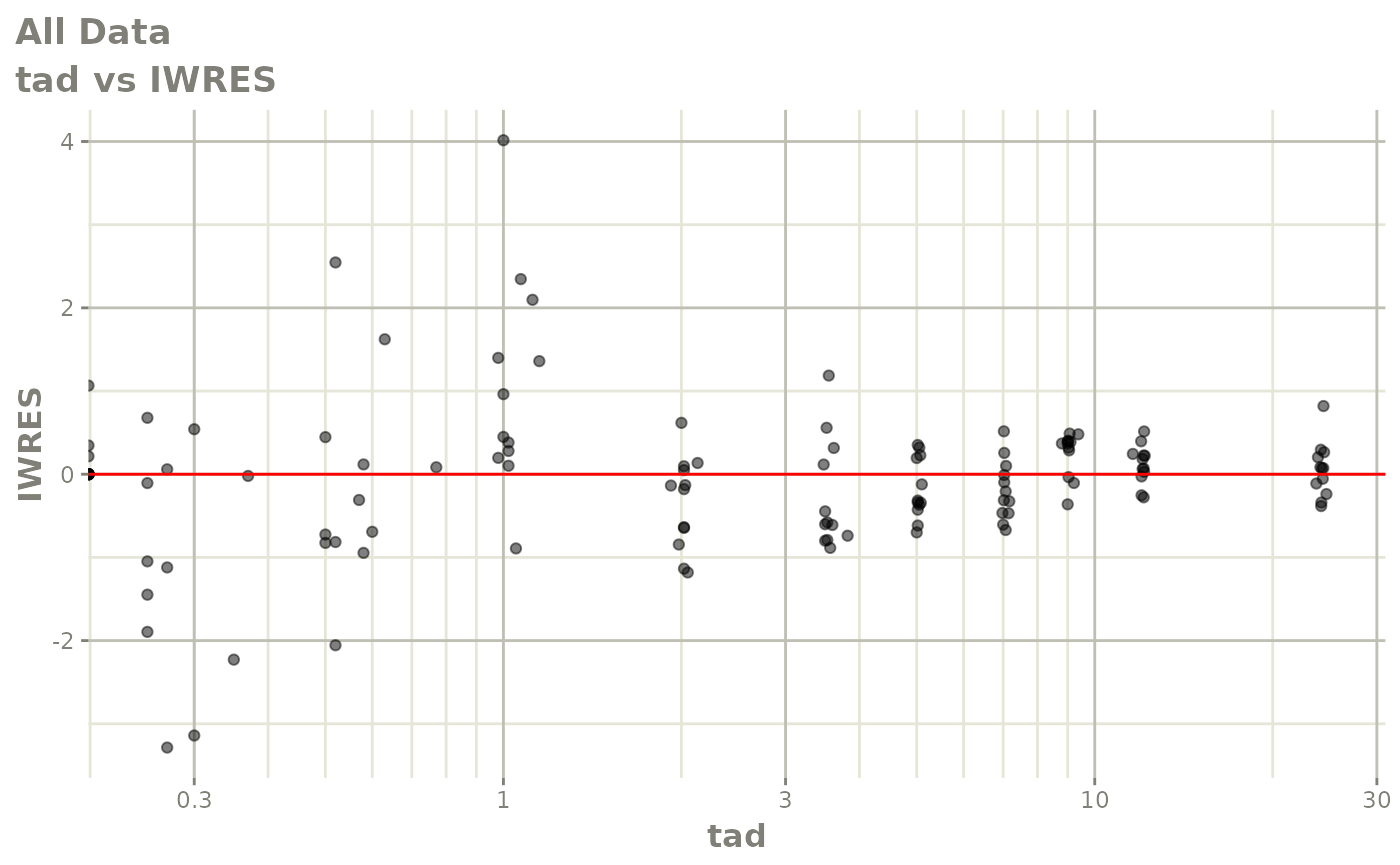
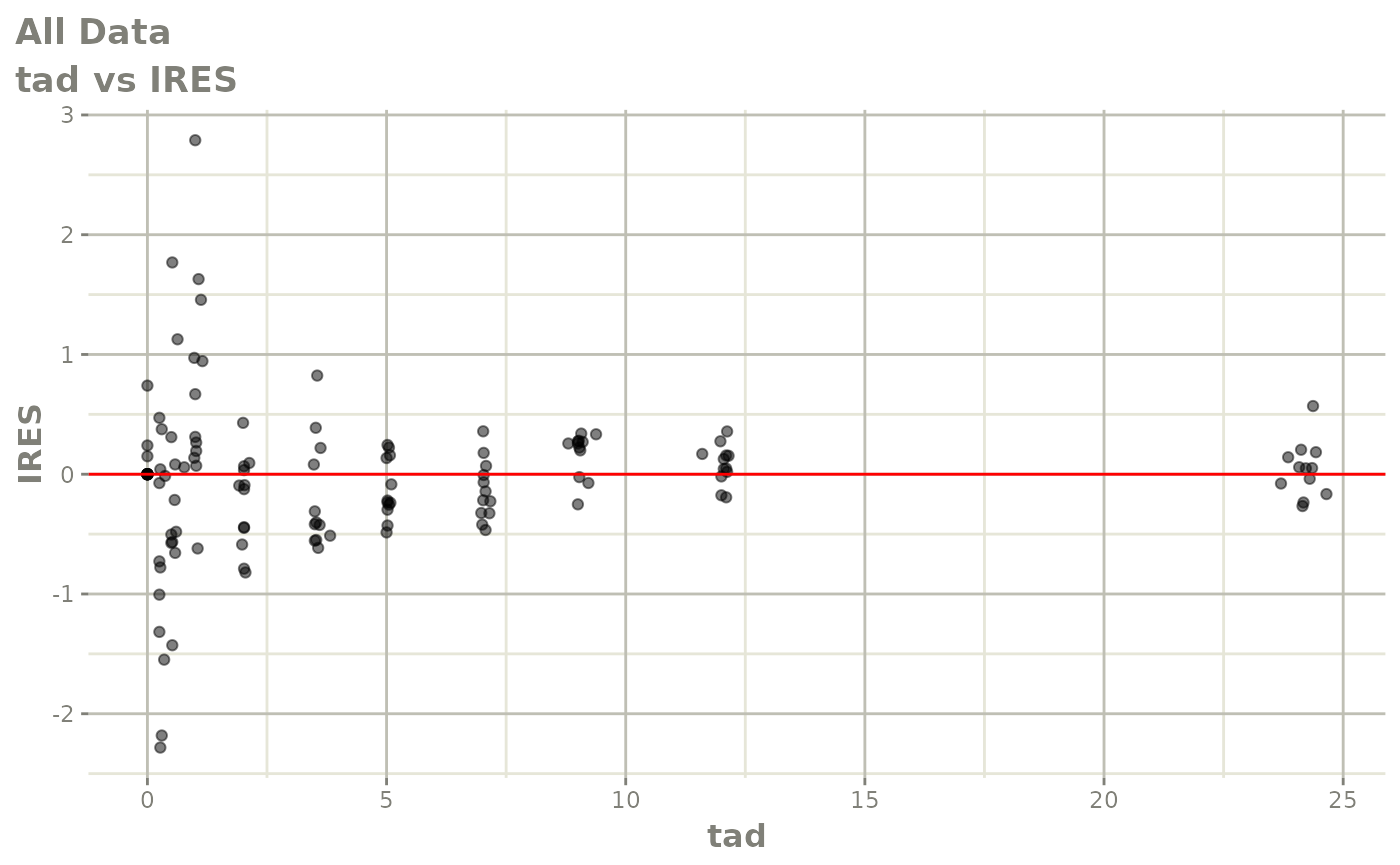
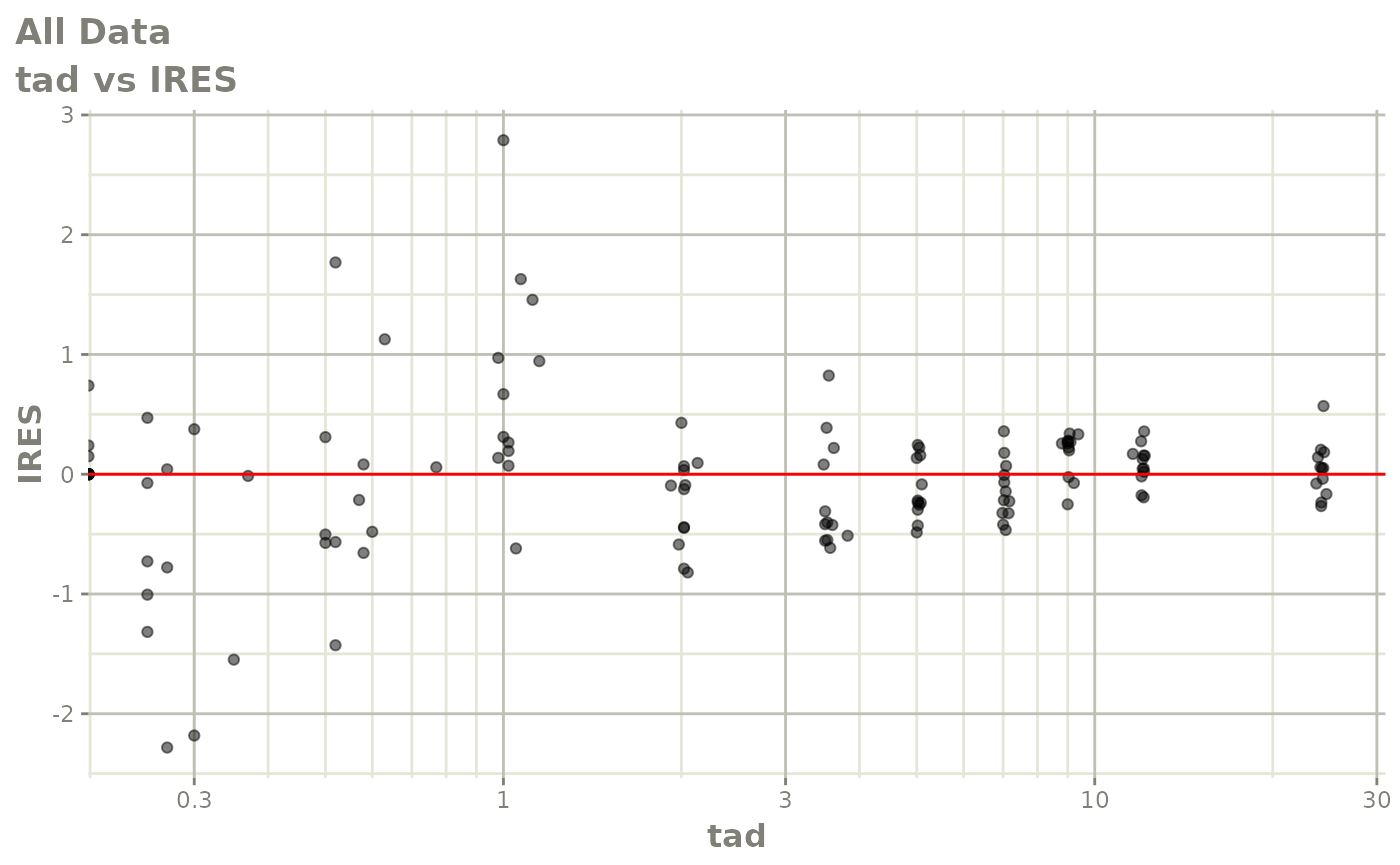
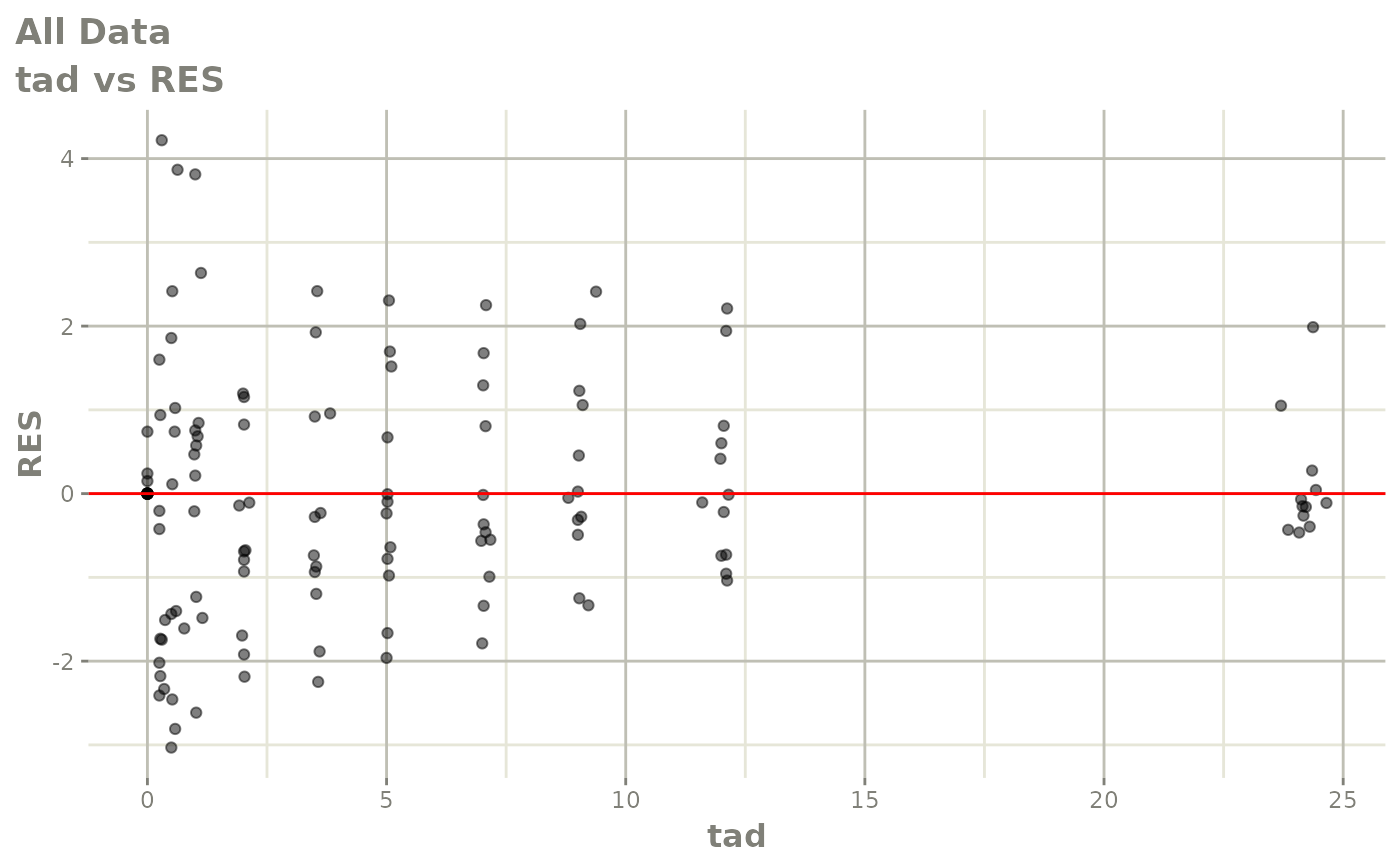
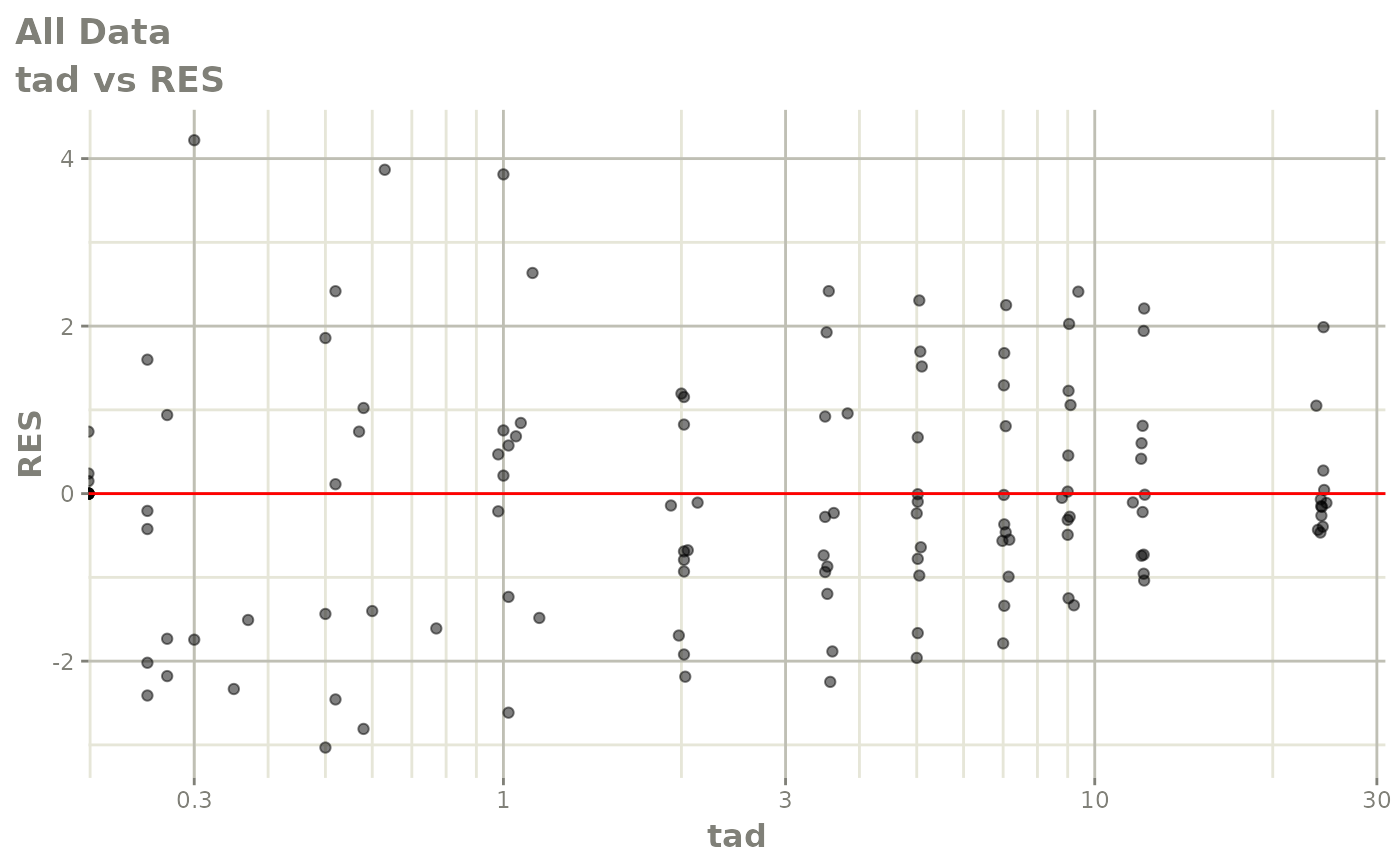
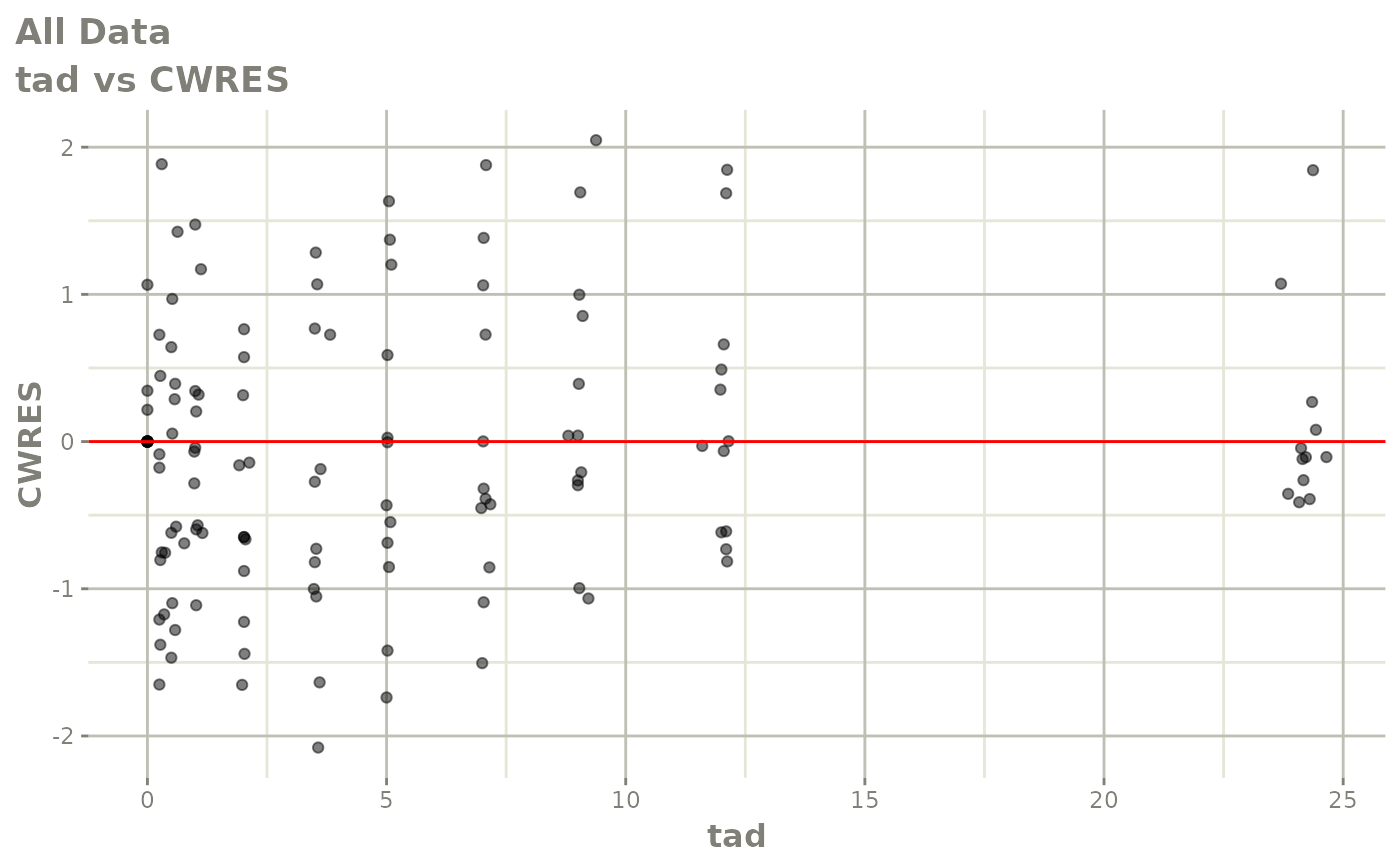
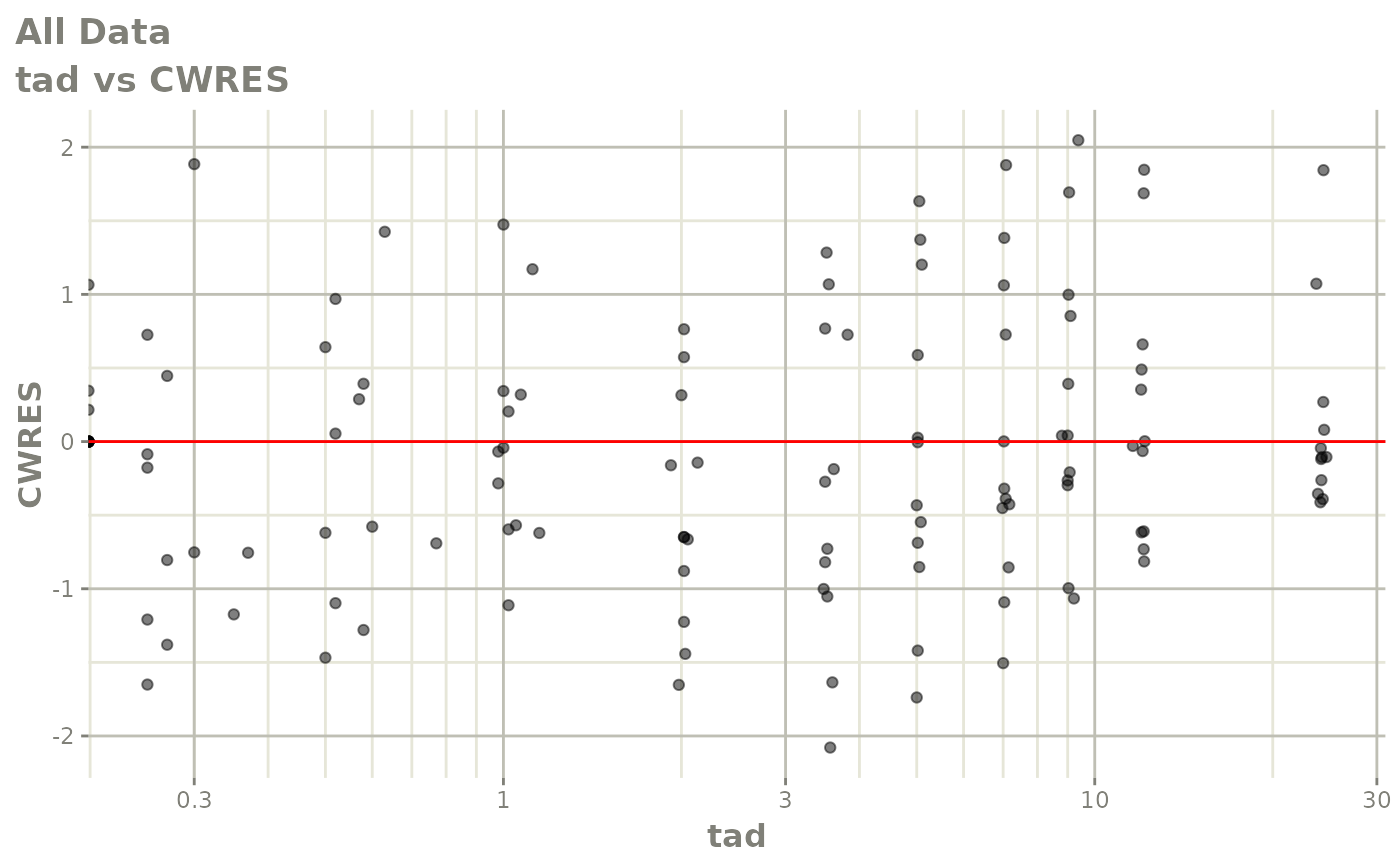
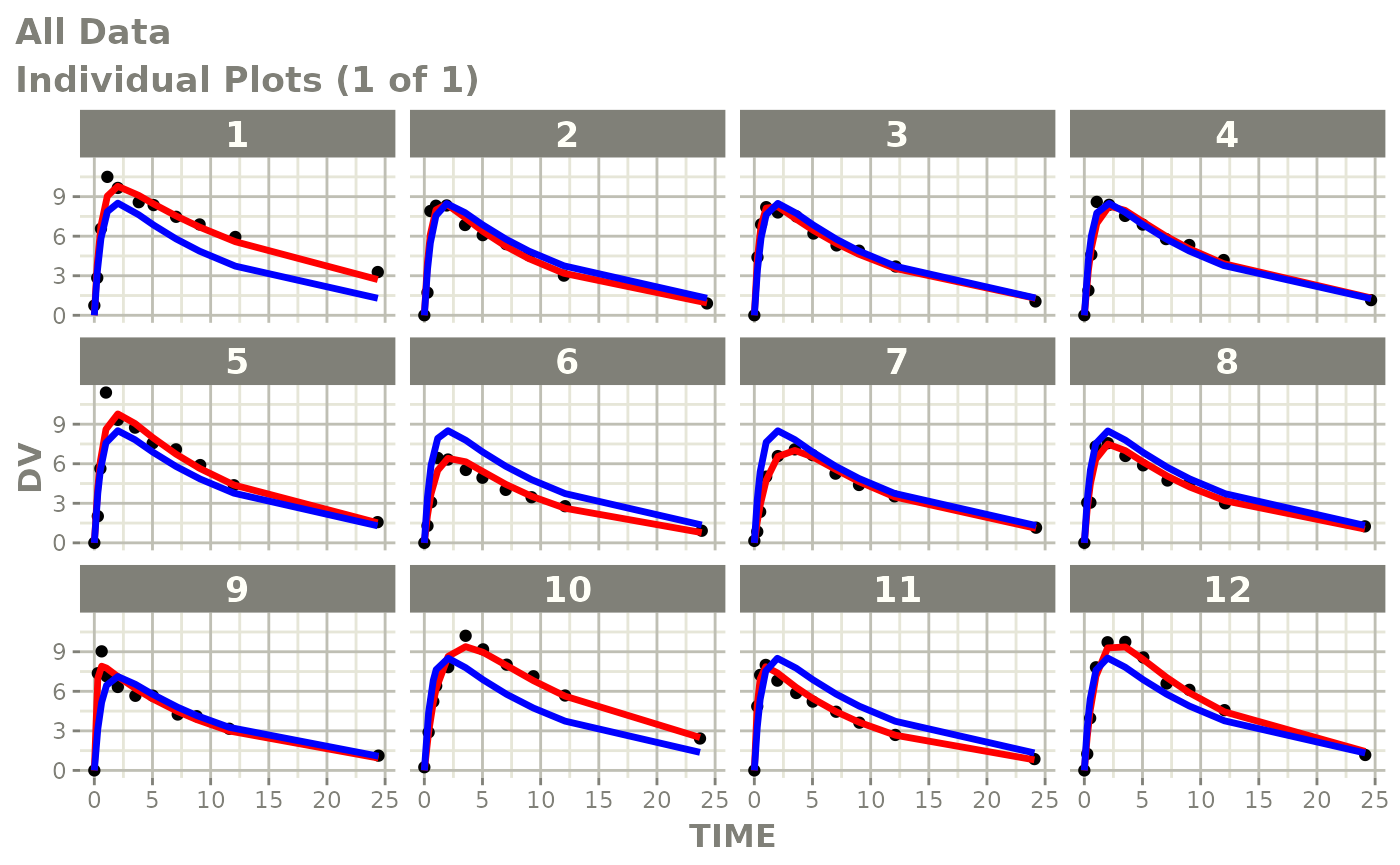
print(fit)
#> ── nlmixr FOCEi (outer: nlminb) fit ────────────────────────────────────────────
#>
#> OBJF AIC BIC Log-likelihood Condition Number
#> FOCEi 116.8035 373.4033 393.5829 -179.7016 68.42019
#>
#> ── Time (sec $time): ───────────────────────────────────────────────────────────
#>
#> setup optimize covariance table other
#> elapsed 5.800482 0.199363 0.199371 0.018 0.686784
#>
#> ── Population Parameters ($parFixed or $parFixedDf): ───────────────────────────
#>
#> Parameter Est. SE %RSE Back-transformed(95%CI) BSV(CV%) Shrink(SD)%
#> tka Log Ka 0.464 0.195 42.1 1.59 (1.08, 2.33) 70.4 1.81%
#> tcl Log Cl 1.01 0.0751 7.42 2.75 (2.37, 3.19) 26.8 3.87%
#> tv log V 3.46 0.0437 1.26 31.8 (29.2, 34.6) 13.9 10.3%
#> add.sd 0.695 0.695
#>
#> Covariance Type ($covMethod): r,s
#> Some strong fixed parameter correlations exist ($cor) :
#> cor:tcl,tka cor:tv,tka cor:tv,tcl
#> 0.158 0.422 0.744
#>
#>
#> No correlations in between subject variability (BSV) matrix
#> Full BSV covariance ($omega) or correlation ($omegaR; diagonals=SDs)
#> Distribution stats (mean/skewness/kurtosis/p-value) available in $shrink
#> Minimization message ($message):
#> relative convergence (4)
#>
#> ── Fit Data (object is a modified tibble): ─────────────────────────────────────
#> # A tibble: 132 × 20
#> ID TIME DV PRED RES WRES IPRED IRES IWRES CPRED CRES
#> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 0 0.74 1.79e-15 0.740 1.07 0 0.74 1.07 -5.61e-16 0.740
#> 2 1 0.25 2.84 3.26e+ 0 -0.423 -0.225 3.85 -1.01 -1.45 3.22e+ 0 -0.379
#> 3 1 0.57 6.57 5.83e+ 0 0.740 0.297 6.78 -0.215 -0.309 5.77e+ 0 0.795
#> # … with 129 more rows, and 9 more variables: CWRES <dbl>, eta.ka <dbl>,
#> # eta.cl <dbl>, eta.v <dbl>, ka <dbl>, cl <dbl>, v <dbl>, tad <dbl>,
#> # dosenum <dbl>
fit$eta
#> ID eta.ka eta.cl eta.v
#> 1 1 0.08633989 -0.47406277 -9.110262e-02
#> 2 2 0.19824403 0.14438007 5.214363e-03
#> 3 3 0.37188038 0.02832174 5.310541e-02
#> 4 4 -0.28167853 -0.01803295 -1.295651e-02
#> 5 5 -0.04256582 -0.15001965 -1.433194e-01
#> 6 6 -0.38597392 0.37218972 1.935431e-01
#> 7 7 -0.77183271 0.14633531 5.515352e-02
#> 8 8 -0.16778000 0.16482442 9.359308e-02
#> 9 9 1.36338837 0.04551583 -6.709389e-05
#> 10 10 -0.73251205 -0.38171082 -1.716858e-01
#> 11 11 0.75433206 0.28790437 1.365735e-01
#> 12 12 -0.51928526 -0.12524871 -2.015633e-01Default trace plots can be generated using:
traceplot(fit)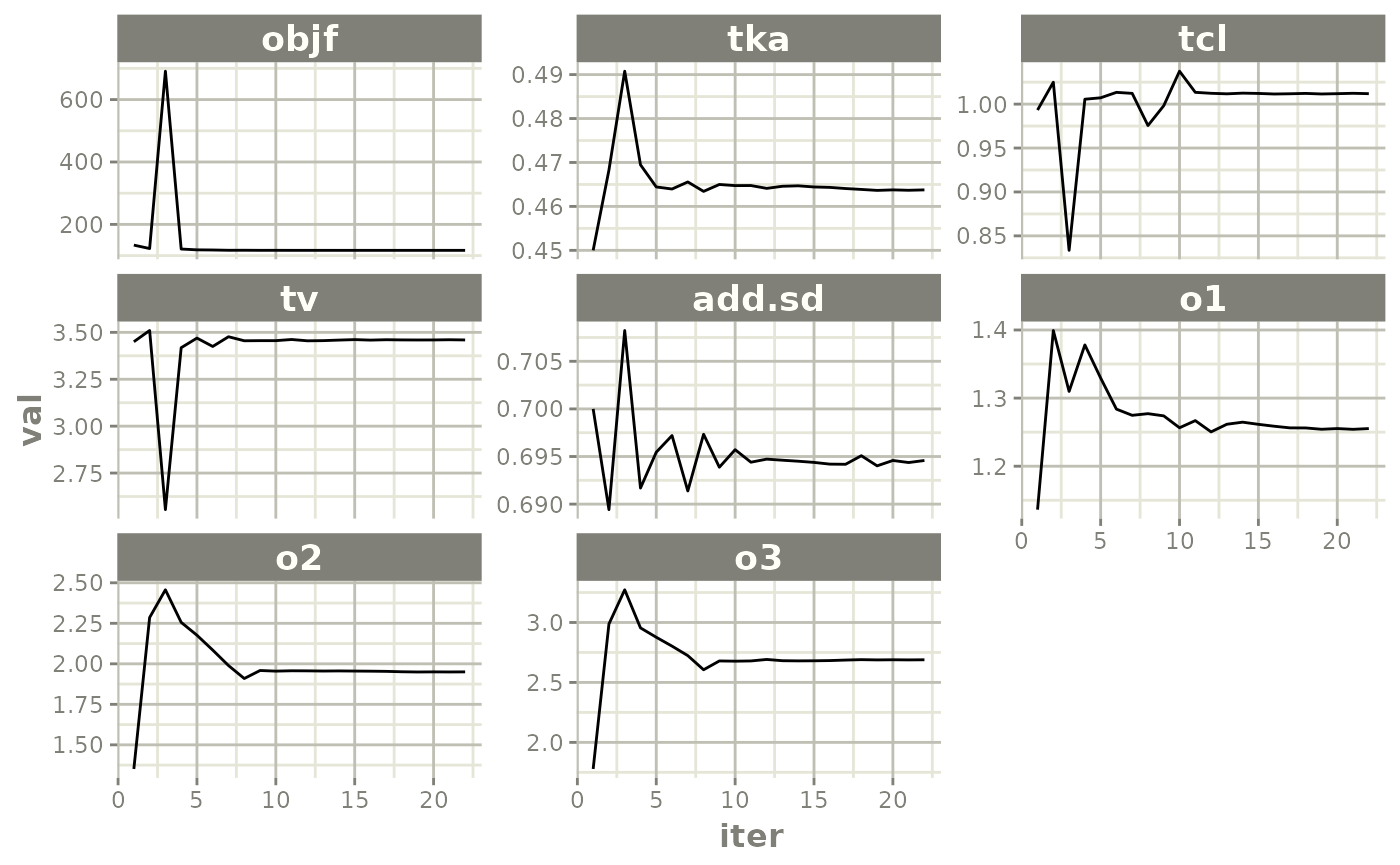
but with a little more work, we can get a nicer set of iteration trace plots (“wriggly worms”)…
iter <- fit2$par.hist.stacked
iter$Parameter[iter$par=="add.sd"] <- "Additive error"
iter$Parameter[iter$par=="eta.cl"] <- "IIV CL/F"
iter$Parameter[iter$par=="eta.v"] <- "IIV V/F"
iter$Parameter[iter$par=="eta.ka"] <- "IIV ka"
iter$Parameter[iter$par=="tcl"] <- "log(CL/F)"
iter$Parameter[iter$par=="tv"] <- "log(V/F)"
iter$Parameter[iter$par=="tka"] <- "log(ka)"
iter$Parameter <- ordered(iter$Parameter, c("log(CL/F)", "log(V/F)", "log(ka)",
"IIV CL/F", "IIV V/F", "IIV ka",
"Additive error"))
ggplot(iter, aes(iter, val)) +
geom_line(col="red") +
scale_x_continuous("Iteration") +
scale_y_continuous("Value") +
facet_wrap(~ Parameter, scales="free_y") +
labs(title="Theophylline single-dose", subtitle="Parameter estimation iterations")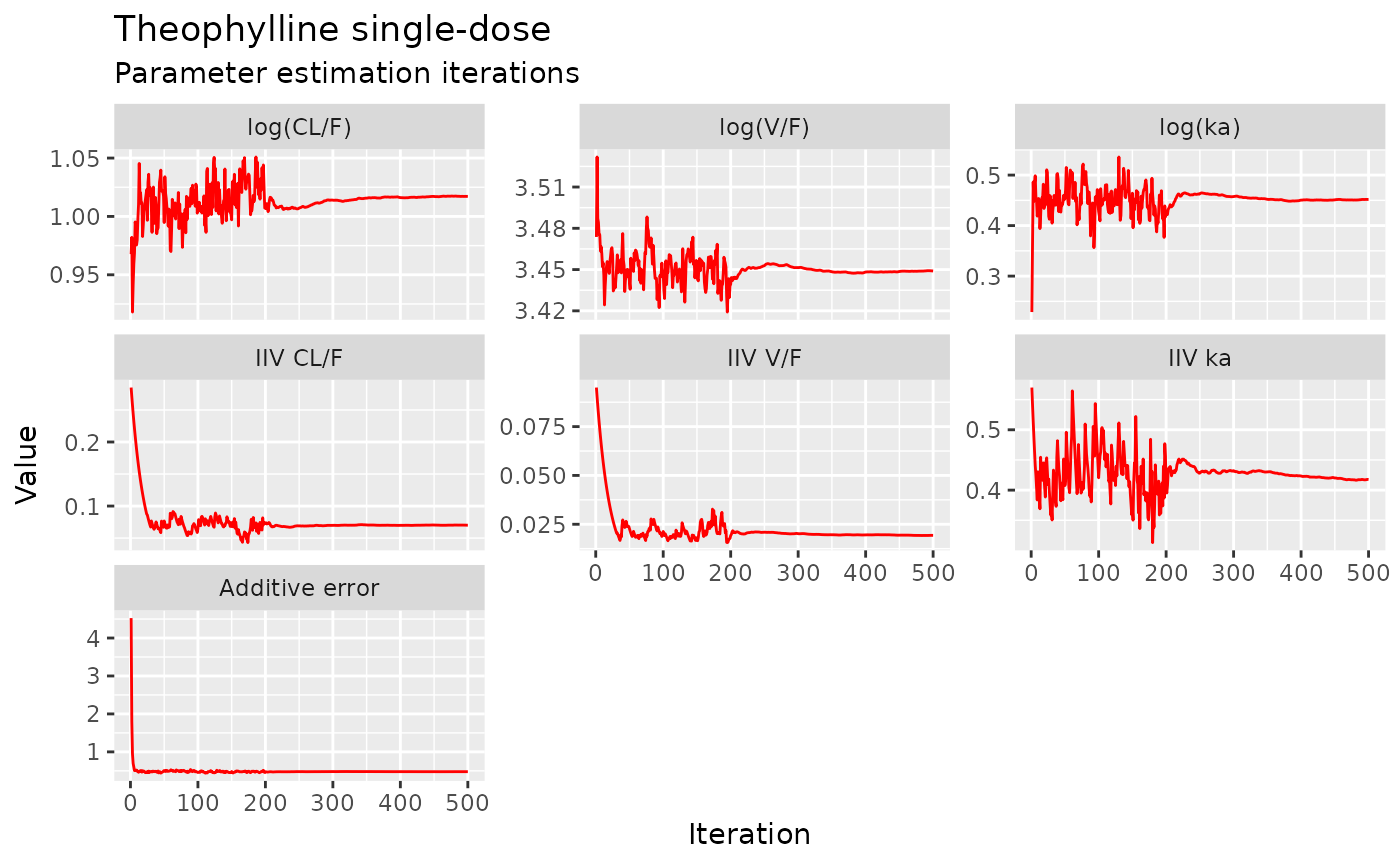
… and some random-effects histograms…
etas <- data.frame(eta = c(fit2$eta$eta.ka, fit2$eta$eta.cl, fit2$eta$eta.v),
lab = rep(c("eta(ka)", "eta(CL/F)", "eta(V/F)"), each=nrow(fit2$eta)))
etas$lab <- ordered(etas$lab, c("eta(CL/F)","eta(V/F)","eta(ka)"))
ggplot(etas, aes(eta)) +
geom_histogram(fill="red", col="white") +
geom_vline(xintercept=0) +
scale_x_continuous(expression(paste(eta))) +
scale_y_continuous("Count") +
facet_grid(~ lab) +
coord_cartesian(xlim=c(-1.75,1.75)) +
labs(title="Theophylline single-dose", subtitle="IIV distributions")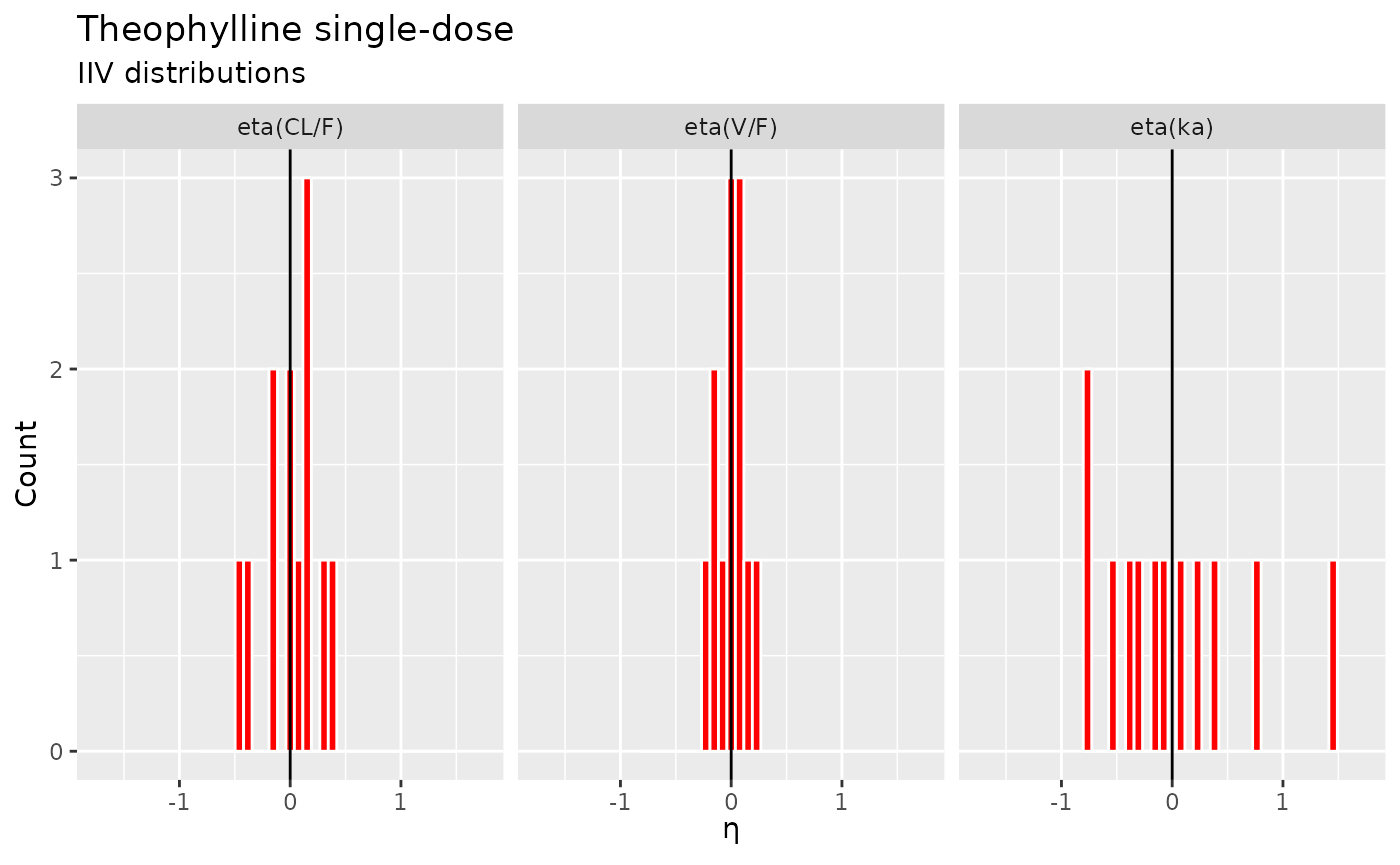
xpose
This is all very nice. But what we really want is a complete suite of model diagnostic tools, like those available in xpose, right?
Restart R, and install xpose from CRAN, if you haven’t already…
Now install the extension for nlmixr:
devtools::install_github("nlmixrdevelopment/xpose.nlmixr")… and convert your nlmixr fit object into an xpose fit object.
library(xpose.nlmixr)
xp <- xpose_data_nlmixr(fit2)
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
dv_vs_pred(xp)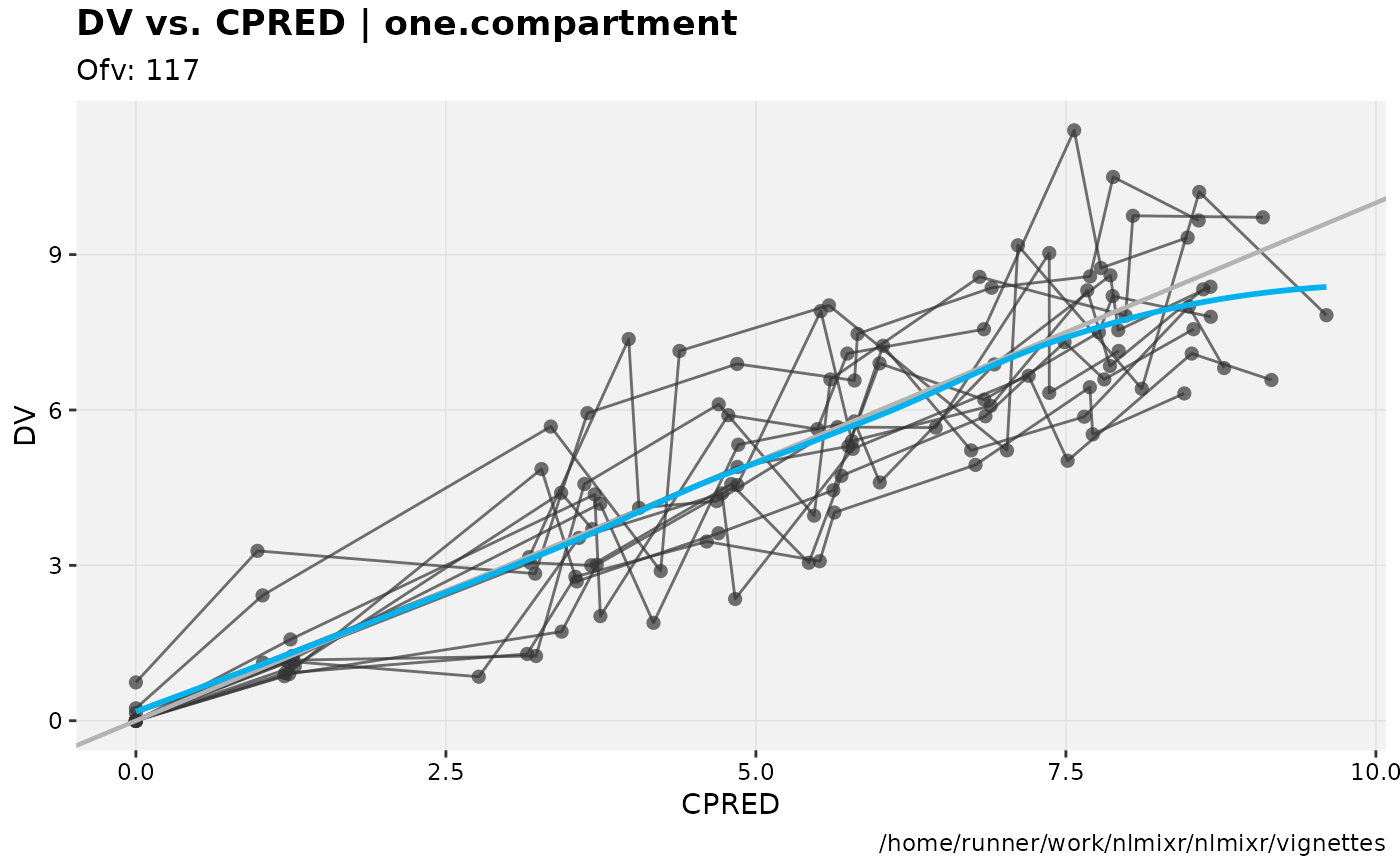
dv_vs_ipred(xp)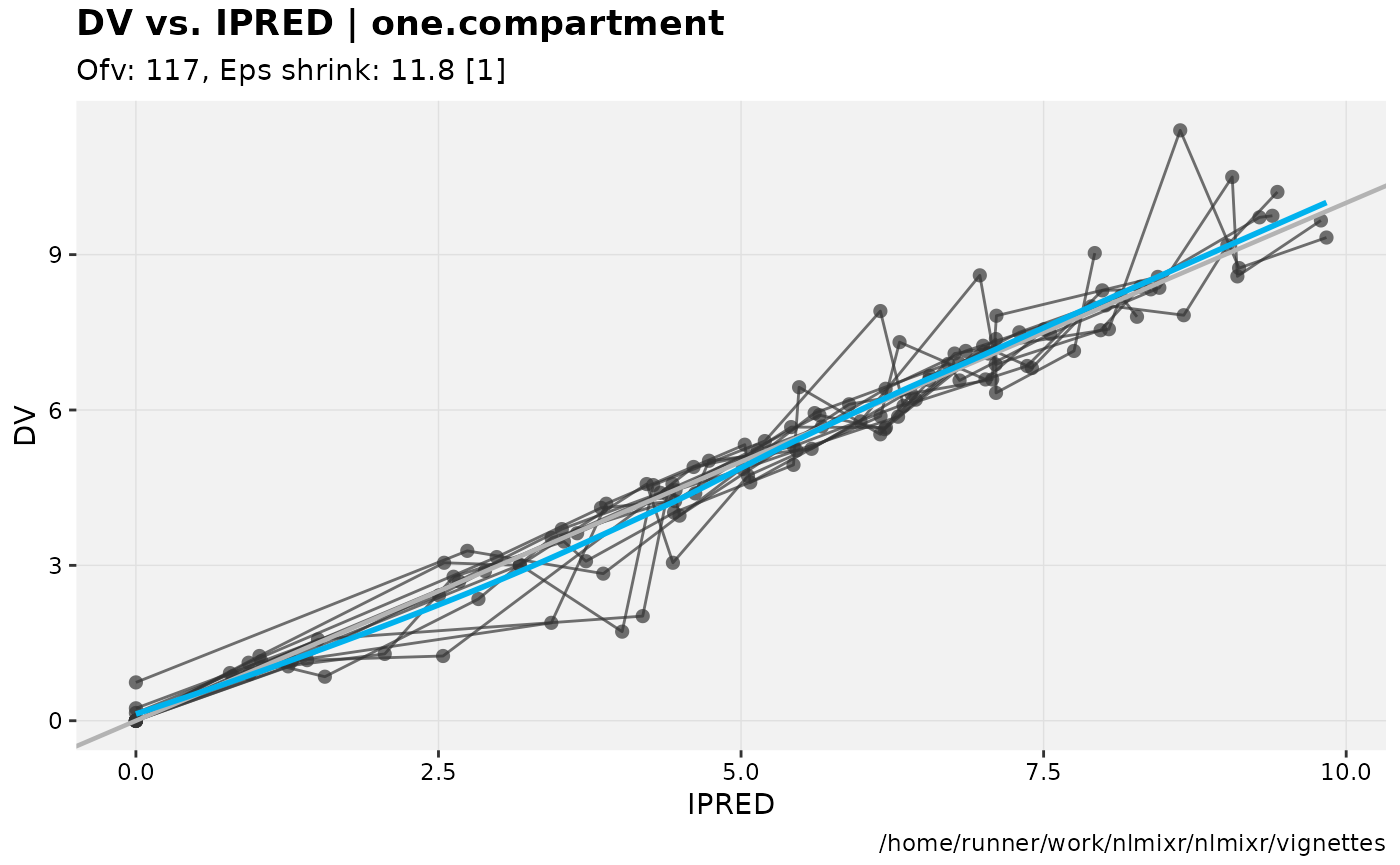
dv_vs_pred(xp)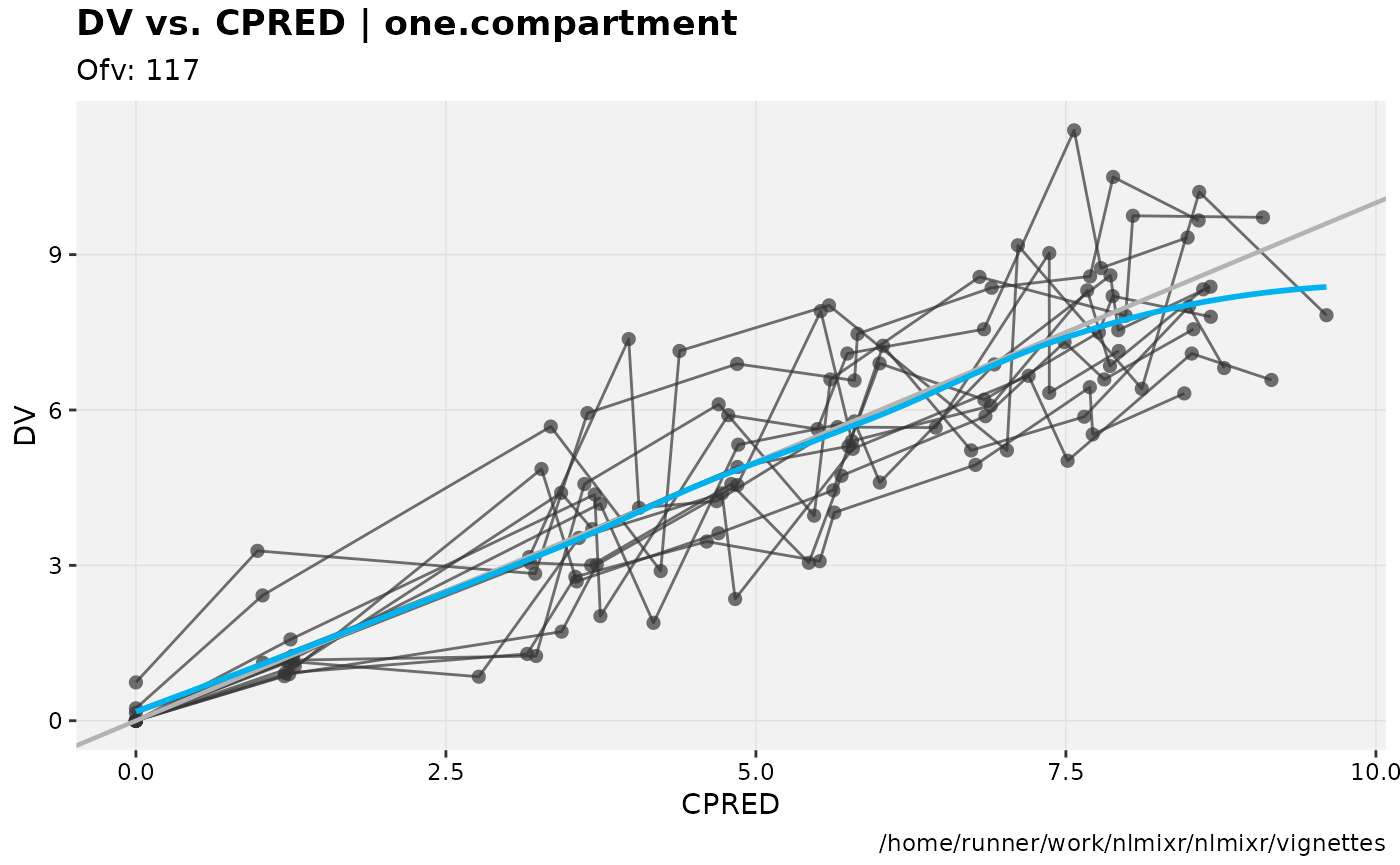
absval_res_vs_pred(xp, res="IWRES")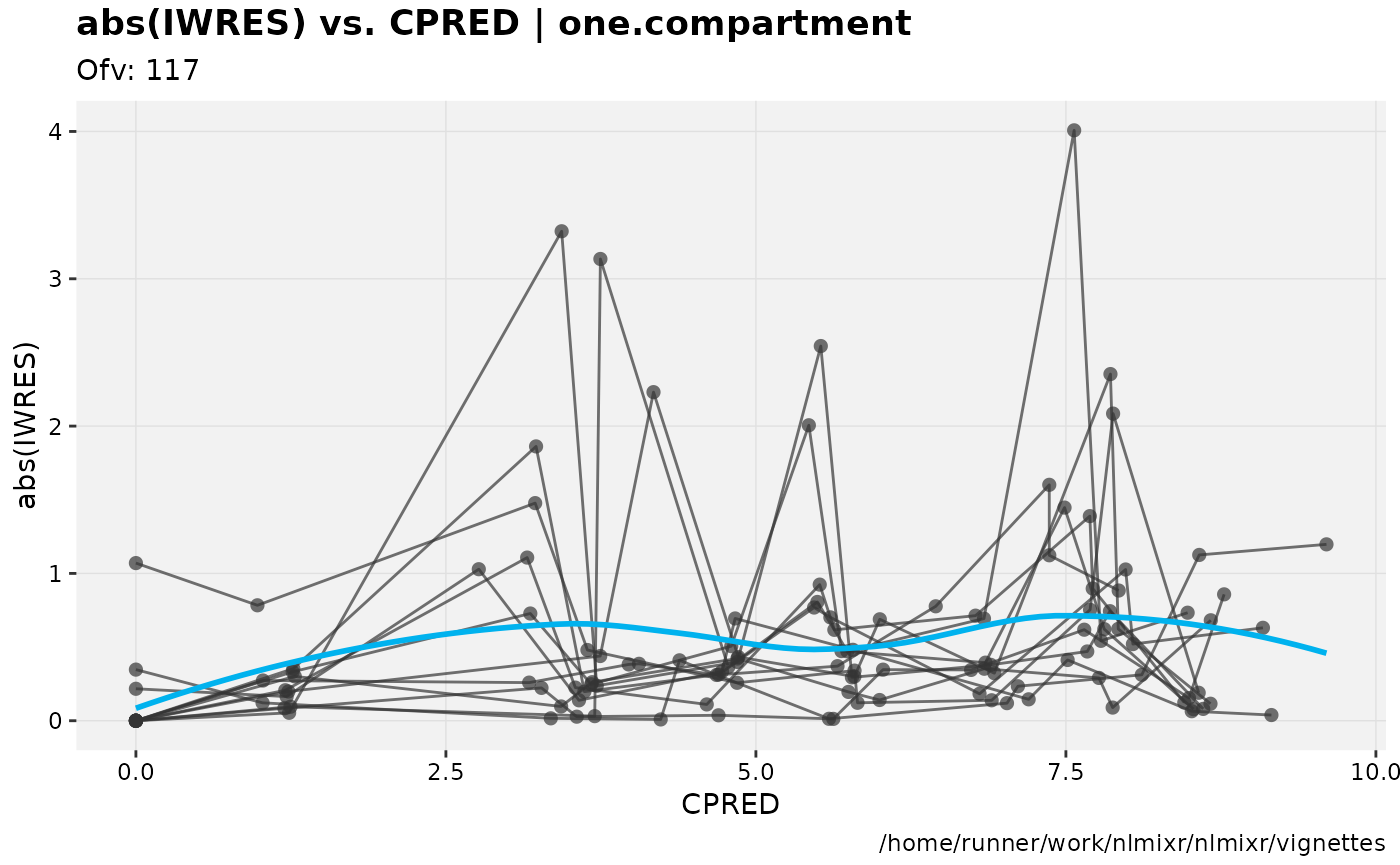 For more information about using xpose, see the Uppsala pharmacometrics group’s comprehensive site here.
For more information about using xpose, see the Uppsala pharmacometrics group’s comprehensive site here.
The UI
The nlmixr modeling dialect, inspired by R and NONMEM, can be used to fit models using all current and future estimation algorithms within nlmixr. Using these widely-used tools as inspiration has the advantage of delivering a model specification syntax that is instantly familiar to the majority of analysts working in pharmacometrics and related fields.
Overall model structure
Model specifications for nlmixr are written using functions containing ini and model blocks. These functions can be called anything, but must contain these two components. Let’s look at a very simple one-compartment model with no covariates.
f <- function() {
ini({ # Initial conditions/variables
# are specified here
})
model({ # The model is specified
# here
})
}The ini block
The ini block specifies initial conditions, including initial estimates and boundaries for those algorithms which support them (currently, the built-in nlme and saem methods do not). Nomenclature is similar to that used in NONMEM, Monolix and other similar packages. In the NONMEM world, the ini block is analogous to $THETA, $OMEGA and $SIGMA blocks.
f <- function() { # Note that arguments to the function are currently
# ignored by nlmixr
ini({
# Initial conditions for population parameters (sometimes
# called THETA parameters) are defined by either '<-' or '='
lCl <- 1.6 # log Cl (L/hr)
# Note that simple expressions that evaluate to a number are
# OK for defining initial conditions (like in R)
lVc = log(90) # log V (L)
## Also, note that a comment on a parameter is captured as a parameter label
lKa <- 1 # log Ka (1/hr)
# Bounds may be specified by c(lower, est, upper), like NONMEM:
# Residuals errors are assumed to be population parameters
prop.err <- c(0, 0.2, 1)
# IIV terms will be discussed in the next example
})
# The model block will be discussed later
model({})
}As shown in the above example:
- Simple parameter values are specified using an R-compatible assignment
- Boundaries may be specified by
c(lower, est, upper). - Like NONMEM,
c(lower,est)is equivalent toc(lower,est,Inf) - Also like NONMEM,
c(est)does not specify a lower bound, and is equivalent to specifying the parameter without using R’sc()function.
These parameters can be named using almost any R-compatible name. Please note that:
- Residual error estimates should be coded as population estimates (i.e. using
=or<-, not~). - Variable names that start with
_are not supported. Note that R does not allow variable starting with_to be assigned without quoting them. - Naming variables that start with
rx_ornlmixr_is not allowed, since RxODE and nlmixr use these prefixes internally for certain estimation routines and for calculating residuals. - Variable names are case-sensitive, just like they are in R.
CLis not the same asCl.
In mixture models, multivariate normal individual deviations from the normal population and parameters are estimated (in NONMEM these are called “ETA” parameters). Additionally, the variance/covariance matrix of these deviations are is also estimated (in NONMEM this is the “OMEGA” matrix). These also take initial estimates. In nlmixr, these are specified by the ~ operator. This that is typically used in statistics R for “modeled by”, and was chosen to distinguish these estimates from the population and residual error parameters.
Continuing from the prior example, we can annotate the estimates for the between-subject error distribution…
f <- function() {
ini({
lCl <- 1.6 # log Cl (L/hr)
lVc = log(90) # log V (L)
lKa <- 1 # log Ka (1/hr)
prop.err <- c(0, 0.2, 1)
# Initial estimate for ka IIV variance
# Labels work for single parameters
eta.ka ~ 0.1 ## BSV Ka
# For correlated parameters, you specify the names of each
# correlated parameter separated by a addition operator `+`
# and the left handed side specifies the lower triangular
# matrix initial of the covariance matrix.
eta.cl + eta.vc ~ c(0.1,
0.005, 0.1)
# Note that labels do not currently work for correlated
# parameters. Also, do not put comments inside the lower
# triangular matrix as this will currently break the model.
})
# The model block will be discussed later
model({})
}As shown in the above example:
- Simple variances are specified by the variable name and the estimate separated by
~. - Correlated parameters are specified by the sum of the variable labels and then the lower triangular matrix of the covariance is specified on the left handed side of the equation. This is also separated by
~. - The initial estimates are specified on the variance scale, and in analogy with NONMEM, the square roots of the diagonal elements correspond to coefficients of variation when used in the exponential IIV implementation.
Currently, comments inside the lower triangular matrix are not allowed.
The model block
The model block specifies the model, and is analogous to the $PK, $PRED and $ERROR blocks in NONMEM.
Once the initialization block has been defined, you can define a model in terms of the variables defined in the ini block. You can also mix RxODE blocks into the model if needed.
The current method of defining a nlmixr model is to specify the parameters, and then any required RxODE lines. Continuing the annotated example:
f <- function() {
ini({
lCl <- 1.6 # log Cl (L/hr)
lVc <- log(90) # log Vc (L)
lKA <- 0.1 # log Ka (1/hr)
prop.err <- c(0, 0.2, 1)
eta.Cl ~ 0.1 # BSV Cl
eta.Vc ~ 0.1 # BSV Vc
eta.KA ~ 0.1 # BSV Ka
})
model({
# Parameters are defined in terms of the previously-defined
# parameter names:
Cl <- exp(lCl + eta.Cl)
Vc = exp(lVc + eta.Vc)
KA <- exp(lKA + eta.KA)
# Next, the differential equations are defined:
kel <- Cl / Vc;
d/dt(depot) = -KA*depot;
d/dt(centr) = KA*depot-kel*centr;
# And the concentration is then calculated
cp = centr / Vc;
# Finally, we specify that the plasma concentration follows
# a proportional error distribution (estimated by the parameter
# prop.err)
cp ~ prop(prop.err)
})
}A few points to note:
- Parameters are defined before the differential equations. Currently directly defining the differential equations in terms of the population parameters is not supported.
- The differential equations, parameters and error terms are in a single block, instead of multiple sections.
- Additionally state names, calculated variables, also cannot start with either
rx_ornlmixr_since these are used internally in some estimation routines. - Errors are specified using the tilde,
~. Currently you can use eitheradd(parameter)for additive error,prop(parameter)for proportional error oradd(parameter1) + prop(parameter2)for combined additive and proportional error. You can also specifynorm(parameter)for additive error, since it follows a normal distribution. - Some routines, like
saem, require parameters expressed in terms ofPop.Parameter + Individual.Deviation.Parameter + Covariate*Covariate.Parameter. The order of these parameters does not matter. This is similar to NONMEM’s mu-referencing, though not as restrictive. This means that forsaem, a parameterization of the formCl <- Cl*exp(eta.Cl)is not allowed. - The type of parameter in the model is determined by the
iniblock; covariates used in the model are not included in theiniblock. These variables need to be present in the modeling dataset for the model to run.
Running models
Models can be fitted several ways, including via the [magrittr] forward-pipe operator.
fit <- nlmixr(one.compartment) %>% saem.fit(data=theo_sd)fit2 <- nlmixr(one.compartment, data=theo_sd, est="saem")fit3 <- one.compartment %>% saem.fit(data=theo_sd)Options to the estimation routines can be specified using nlmeControl for nlme estimation:
fit4 <- nlmixr(one.compartment, theo_sd,est="nlme",control = nlmeControl(pnlsTol = .5))where options are specified in the nlme documentation. Options for saem can be specified using saemControl:
fit5 <- nlmixr(one.compartment,theo_sd,est="saem",control=saemControl(n.burn=250,n.em=350,print=50))this example specifies 250 burn-in iterations, 350 em iterations and a print progress every 50 runs.
Model Syntax for solved PK systems
Solved PK systems are also currently supported by nlmixr with the ‘linCmt()’ pseudo-function. An annotated example of a solved system is below:
f <- function(){
ini({
lCl <- 1.6 #log Cl (L/hr)
lVc <- log(90) #log Vc (L)
lKA <- 0.1 #log Ka (1/hr)
prop.err <- c(0, 0.2, 1)
eta.Cl ~ 0.1 # BSV Cl
eta.Vc ~ 0.1 # BSV Vc
eta.KA ~ 0.1 # BSV Ka
})
model({
Cl <- exp(lCl + eta.Cl)
Vc = exp(lVc + eta.Vc)
KA <- exp(lKA + eta.KA)
## Instead of specifying the ODEs, you can use
## the linCmt() function to use the solved system.
##
## This function determines the type of PK solved system
## to use by the parameters that are defined. In this case
## it knows that this is a one-compartment model with first-order
## absorption.
linCmt() ~ prop(prop.err)
})
}A few things to keep in mind: * Currently the solved systems support either oral dosing, IV dosing or IV infusion dosing and does not allow mixing the dosing types. * While RxODE allows mixing of solved systems and ODEs, this has not been implemented in nlmixr yet. * The solved systems implemented are the one, two and three compartment models with or without first-order absorption. Each of the models support a lag time with a tlag parameter. * In general the linear compartment model figures out the model by the parameter names. nlmixr currently knows about numbered volumes, Vc/Vp, Clearances in terms of both Cl and Q/CLD. Additionally nlmixr knows about elimination micro-constants (ie K12). Mixing of these parameters for these models is currently not supported.
Checking model syntax
After specifying the model syntax you can check that nlmixr is interpreting it correctly by using the nlmixr function on it. Using the above function we can get:
nlmixr(f)
#> ▂▂ RxODE-based 1-compartment model with first-order absorption ▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂
#> ── Initialization: ─────────────────────────────────────────────────────────────
#> Fixed Effects ($theta):
#> lCl lVc lKA
#> 1.60000 4.49981 0.10000
#>
#> Omega ($omega):
#> eta.Cl eta.Vc eta.KA
#> eta.Cl 0.1 0.0 0.0
#> eta.Vc 0.0 0.1 0.0
#> eta.KA 0.0 0.0 0.1
#> ── μ-referencing ($muRefTable): ────────────────────────────────────────────────
#> ┌─────────┬─────────┐
#> │ theta │ eta │
#> ├─────────┼─────────┤
#> │ lCl │ eta.Cl │
#> ├─────────┼─────────┤
#> │ lVc │ eta.Vc │
#> ├─────────┼─────────┤
#> │ lKA │ eta.KA │
#> └─────────┴─────────┘
#>
#> ── Model: ──────────────────────────────────────────────────────────────────────
#> Cl <- exp(lCl + eta.Cl)
#> Vc = exp(lVc + eta.Vc)
#> KA <- exp(lKA + eta.KA)
#> ## Instead of specifying the ODEs, you can use
#> ## the linCmt() function to use the solved system.
#> ##
#> ## This function determines the type of PK solved system
#> ## to use by the parameters that are defined. In this case
#> ## it knows that this is a one-compartment model with first-order
#> ## absorption.
#> linCmt() ~ prop(prop.err)
#> ▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂In general this gives you information about the model (what type of solved system/RxODE), initial estimates as well as the code for the model block.