nlmixr
The broom and broom.mixed packages
broom and broom.mixed are packages that attempt to put standard model outputs into data frames. nlmixr supports the tidy and glance methods but does not support augment at this time.
Using a model with a covariance term, the Phenobarbital model, we can explore the different types of output that is used in the tidy functions.
To explore this, first we run the model:
library(nlmixr)
library(broom.mixed)
pheno <- function() {
# Pheno with covariance
ini({
tcl <- log(0.008) # typical value of clearance
tv <- log(0.6) # typical value of volume
## var(eta.cl)
eta.cl + eta.v ~ c(1,
0.01, 1) ## cov(eta.cl, eta.v), var(eta.v)
# interindividual variability on clearance and volume
add.err <- 0.1 # residual variability
})
model({
cl <- exp(tcl + eta.cl) # individual value of clearance
v <- exp(tv + eta.v) # individual value of volume
ke <- cl / v # elimination rate constant
d/dt(A1) = - ke * A1 # model differential equation
cp = A1 / v # concentration in plasma
cp ~ add(add.err) # define error model
})
}
## We will run it two ways to allow comparisons
fit.s <- nlmixr(pheno, pheno_sd, "saem", control=list(logLik=TRUE, print=0),
table=list(cwres=TRUE, npde=TRUE))
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> Error in .fitFun(.ret) :
#> function 'rx_12fb0b0f187565a604fe58aebc4e25d6__calc_lhs' not provided by package 'rx_12fb0b0f187565a604fe58aebc4e25d6_'
#> Error in (function (data, inits, PKpars, model = NULL, pred = NULL, err = NULL, :
#> Could not fit data.
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#>
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
fit.f <- nlmixr(pheno, pheno_sd, "focei",
control=list(print=0),
table=list(cwres=TRUE, npde=TRUE))
#> calculating covariance matrix
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00
#> done
#> [====|====|====|====|====|====|====|====|====|====] 0:00:00Glancing at the goodness of fit metrics
Often in fitting data, you would want to glance at the fit to see how well it fits. In broom, glance will give a summary of the fit metrics of goodness of fit:
glance(fit.s)
#> # A tibble: 1 × 5
#> OBJF AIC BIC logLik conditionNumber
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 722. 1019. 1037. -503. 7.85Note in nlmixr it is possible to have more than one fit metric (based on different quadratures, FOCEi approximation etc). However, the glance only returns the fit metrics that are current.
If you wish you can set the objective function to the focei objective function (which was already calculated with CWRES).
setOfv(fit.s,"gauss3_1.6")Now the glance gives the gauss3_1.6 values.
glance(fit.s)
#> # A tibble: 1 × 5
#> OBJF AIC BIC logLik conditionNumber
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 722. 1019. 1037. -503. 7.85Of course you can always change the type of objective function that nlmixr uses:
setOfv(fit.s,"FOCEi") # Setting objective function to foceiBy setting it back to the SAEM default objective function of FOCEi, the glance(fit.s) has the same values again:
glance(fit.s)
#> # A tibble: 1 × 5
#> OBJF AIC BIC logLik conditionNumber
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 689. 986. 1004. -487. 7.85For convenience, you can do this while you glance at the objects:
glance(fit.s, type="FOCEi")
#> # A tibble: 1 × 5
#> OBJF AIC BIC logLik conditionNumber
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 689. 986. 1004. -487. 7.85Tidying the model parameters
Tidying of overall fit parameters
You can also tidy the model estimates into a data frame with broom for processing. This can be useful when integrating into 3rd parting modeling packages. With a consistent parameter format, tasks for multiple types of models can be automated and applied.
The default function for this is tidy, which when applied to the fit object provides the overall parameter information in a tidy dataset:
tidy(fit.s)
#> # A tibble: 6 × 7
#> effect group term estimate std.error statistic p.value
#> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 fixed NA tcl -5.01 0.0770 -65.1 1 e+ 0
#> 2 fixed NA tv 0.351 0.0530 6.62 3.04e-10
#> 3 ran_pars ID sd__eta.cl 0.511 NA NA NA
#> 4 ran_pars ID sd__eta.v 0.388 NA NA NA
#> 5 ran_pars ID cor__eta.v.eta.… 0.987 NA NA NA
#> 6 ran_pars Residual(add) add.err 2.84 NA NA NA Note by default these are the parameters that are actually estimated in nlmixr, not the back-transformed values in the table from the printout. Of course, with mu-referenced models, you may want to exponentiate some of the terms. The broom package allows you to apply exponentiation on all the parameters, that is:
## Transformation applied on every parameter
tidy(fit.s, exponentiate=TRUE)
#> # A tibble: 6 × 7
#> effect group term estimate std.error statistic p.value
#> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 fixed NA tcl 0.00666 0.000513 13.0 1.41e-26
#> 2 fixed NA tv 1.42 0.0754 18.9 1.36e-41
#> 3 ran_pars ID sd__eta.cl 0.511 NA NA NA
#> 4 ran_pars ID sd__eta.v 0.388 NA NA NA
#> 5 ran_pars ID cor__eta.v.eta.… 0.987 NA NA NA
#> 6 ran_pars Residual(add) add.err 2.84 NA NA NA Note:, in accordance with the rest of the broom package, when the parameters with the exponentiated, the standard errors are transformed to an approximate standard error by the formula: \(\textrm{se}(\exp(x)) \approx \exp(\textrm{model estimate}_x)\times \textrm{se}_x\). This can be confusing because the confidence intervals (described later) are using the actual standard error and back-transforming to the exponentiated scale. This is the reason why the default for nlmixr’s broom interface is exponentiate=FALSE, that is:
tidy(fit.s, exponentiate=FALSE) ## No transformation applied
#> # A tibble: 6 × 7
#> effect group term estimate std.error statistic p.value
#> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 fixed NA tcl -5.01 0.0770 -65.1 1 e+ 0
#> 2 fixed NA tv 0.351 0.0530 6.62 3.04e-10
#> 3 ran_pars ID sd__eta.cl 0.511 NA NA NA
#> 4 ran_pars ID sd__eta.v 0.388 NA NA NA
#> 5 ran_pars ID cor__eta.v.eta.… 0.987 NA NA NA
#> 6 ran_pars Residual(add) add.err 2.84 NA NA NA If you want, you can also use the parsed back-transformation that is used in nlmixr tables (ie fit$parFixedDf). Please note that this uses the approximate back-transformation for standard errors on the log-scaled back-transformed values.
This is done by:
## Transformation applied to log-scaled population parameters
tidy(fit.s, exponentiate=NA)
#> # A tibble: 6 × 7
#> effect group term estimate std.error statistic p.value
#> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 fixed NA tcl 0.00666 0.000513 13.0 1.41e-26
#> 2 fixed NA tv 1.42 0.0754 18.9 1.36e-41
#> 3 ran_pars ID sd__eta.cl 0.511 NA NA NA
#> 4 ran_pars ID sd__eta.v 0.388 NA NA NA
#> 5 ran_pars ID cor__eta.v.eta.… 0.987 NA NA NA
#> 6 ran_pars Residual(add) add.err 2.84 NA NA NA Also note, at the time of this writing the default separator between variables is ., which doesn’t work well with this model giving cor__eta.v.eta.cl. You can easily change this by:
options(broom.mixed.sep2="..")
tidy(fit.s)
#> # A tibble: 6 × 7
#> effect group term estimate std.error statistic p.value
#> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 fixed NA tcl -5.01 0.0770 -65.1 1 e+ 0
#> 2 fixed NA tv 0.351 0.0530 6.62 3.04e-10
#> 3 ran_pars ID sd__eta.cl 0.511 NA NA NA
#> 4 ran_pars ID sd__eta.v 0.388 NA NA NA
#> 5 ran_pars ID cor__eta.v..eta… 0.987 NA NA NA
#> 6 ran_pars Residual(add) add.err 2.84 NA NA NA This gives an easier way to parse value: cor__eta.v..eta.cl
Adding a confidence interval to the parameters
The default R method confint works with nlmixr fit objects:
confint(fit.s)
#> model.est estimate 2.5 % 97.5 %
#> tcl -5.0111306 0.006663365 -5.1620308 -4.8602304
#> tv 0.3511642 1.420720586 0.2472002 0.4551282
#> add.err 2.8357996 2.835799581 NA NAThis transforms the variables as described above. You can still use the exponentiate parameter to control the display of the confidence interval:
confint(fit.s, exponentiate=FALSE)
#> model.est estimate 2.5 % 97.5 %
#> tcl -5.0111306 0.006663365 -5.1620308 -4.8602304
#> tv 0.3511642 1.420720586 0.2472002 0.4551282
#> add.err 2.8357996 2.835799581 NA NAHowever, broom has also implemented it own way to make these data a tidy dataset. The easiest way to get these values in a nlmixr dataset is to use:
tidy(fit.s, conf.level=0.9)
#> # A tibble: 6 × 9
#> effect group term estimate std.error statistic p.value conf.low conf.high
#> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 fixed NA tcl -5.01 0.0770 -65.1 1 e+ 0 -5.14 -4.88
#> 2 fixed NA tv 0.351 0.0530 6.62 3.04e-10 0.264 0.438
#> 3 ran_pars ID sd__… 0.511 NA NA NA NA NA
#> 4 ran_pars ID sd__… 0.388 NA NA NA NA NA
#> 5 ran_pars ID cor_… 0.987 NA NA NA NA NA
#> 6 ran_pars Resi… add.… 2.84 NA NA NA NA NAThe confidence interval is on the scale specified by exponentiate, by default the estimated scale.
If you want to have the confidence on the adaptive back-transformed scale, you would simply use the following:
tidy(fit.s, conf.level=0.9, exponentiate=NA)
#> # A tibble: 6 × 9
#> effect group term estimate std.error statistic p.value conf.low conf.high
#> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 fixed NA tcl 0.00666 0.000513 13.0 1.41e-26 0.00587 0.00756
#> 2 fixed NA tv 1.42 0.0754 18.9 1.36e-41 1.30 1.55
#> 3 ran_pars ID sd__… 0.511 NA NA NA NA NA
#> 4 ran_pars ID sd__… 0.388 NA NA NA NA NA
#> 5 ran_pars ID cor_… 0.987 NA NA NA NA NA
#> 6 ran_pars Resi… add.… 2.84 NA NA NA NA NAExtracting other model information with tidy
The type of information that is extracted can be controlled by the effects argument.
Extracting only fixed effect parameters
The fixed effect parameters can be extracted by effects="fixed"
tidy(fit.s, effects="fixed")
#> # A tibble: 2 × 6
#> effect term estimate std.error statistic p.value
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 fixed tcl -5.01 0.0770 -65.1 1 e+ 0
#> 2 fixed tv 0.351 0.0530 6.62 3.04e-10Extracting only random parameters
The random standard deviations can be extracted by effects="ran_pars":
tidy(fit.s, effects="ran_pars")
#> # A tibble: 4 × 4
#> effect group term estimate
#> <chr> <chr> <chr> <dbl>
#> 1 ran_pars ID sd__eta.cl 0.511
#> 2 ran_pars ID sd__eta.v 0.388
#> 3 ran_pars ID cor__eta.v..eta.cl 0.987
#> 4 ran_pars Residual(add) add.err 2.84Extracting random values (also called ETAs)
The random values, or in NONMEM the ETAs, can be extracted by effects="ran_vals" or effects="random"
head(tidy(fit.s, effects="ran_vals"))
#> # A tibble: 6 × 5
#> effect group level term estimate
#> <chr> <chr> <int> <fct> <dbl>
#> 1 ran_vals ID 1 eta.cl -0.0758
#> 2 ran_vals ID 2 eta.cl -0.218
#> 3 ran_vals ID 3 eta.cl 0.271
#> 4 ran_vals ID 4 eta.cl -0.558
#> 5 ran_vals ID 5 eta.cl 0.328
#> 6 ran_vals ID 6 eta.cl -0.128This duplicate method of running effects is because the broom package supports effects="random" while the broom.mixed package supports effects="ran_vals".
Extracting random coefficients
Random coefficients are the population fixed effect parameter + the random effect parameter, possibly transformed to the correct scale.
In this case we can extract this information from a nlmixr fit object by:
head(tidy(fit.s, effects="ran_coef"))
#> # A tibble: 6 × 5
#> effect group level term estimate
#> <chr> <chr> <int> <fct> <dbl>
#> 1 ran_coef ID 1 tcl -5.09
#> 2 ran_coef ID 2 tcl -5.23
#> 3 ran_coef ID 3 tcl -4.74
#> 4 ran_coef ID 4 tcl -5.57
#> 5 ran_coef ID 5 tcl -4.68
#> 6 ran_coef ID 6 tcl -5.14This can also be changed by the exponentiate argument:
head(tidy(fit.s, effects="ran_coef", exponentiate=NA))
#> # A tibble: 6 × 5
#> effect group level term estimate
#> <chr> <chr> <int> <fct> <dbl>
#> 1 ran_coef ID 1 tcl 0.00618
#> 2 ran_coef ID 2 tcl 0.00536
#> 3 ran_coef ID 3 tcl 0.00874
#> 4 ran_coef ID 4 tcl 0.00381
#> 5 ran_coef ID 5 tcl 0.00925
#> 6 ran_coef ID 6 tcl 0.00586
head(tidy(fit.s, effects="ran_coef", exponentiate=TRUE))
#> # A tibble: 6 × 5
#> effect group level term estimate
#> <chr> <chr> <int> <fct> <dbl>
#> 1 ran_coef ID 1 tcl 0.00618
#> 2 ran_coef ID 2 tcl 0.00536
#> 3 ran_coef ID 3 tcl 0.00874
#> 4 ran_coef ID 4 tcl 0.00381
#> 5 ran_coef ID 5 tcl 0.00925
#> 6 ran_coef ID 6 tcl 0.00586Example of using a tidy model estimates for other packages
Dotwhisker
As explained above, this standard format makes it easier for tidyverse packages to interact with model information. An example of this is piping the tidy information to dplyr to filter the effects and then to the dotwhisker package to plot the model parameter confidence intervals.
options(broom.mixed.sep2=": ", broom.mixed.sep2=", ")
library(ggplot2)
library(dotwhisker)
library(dplyr)
fit.s %>%
tidy(exponentiate=NA) %>%
filter(effect=="fixed") %>%
dwplot()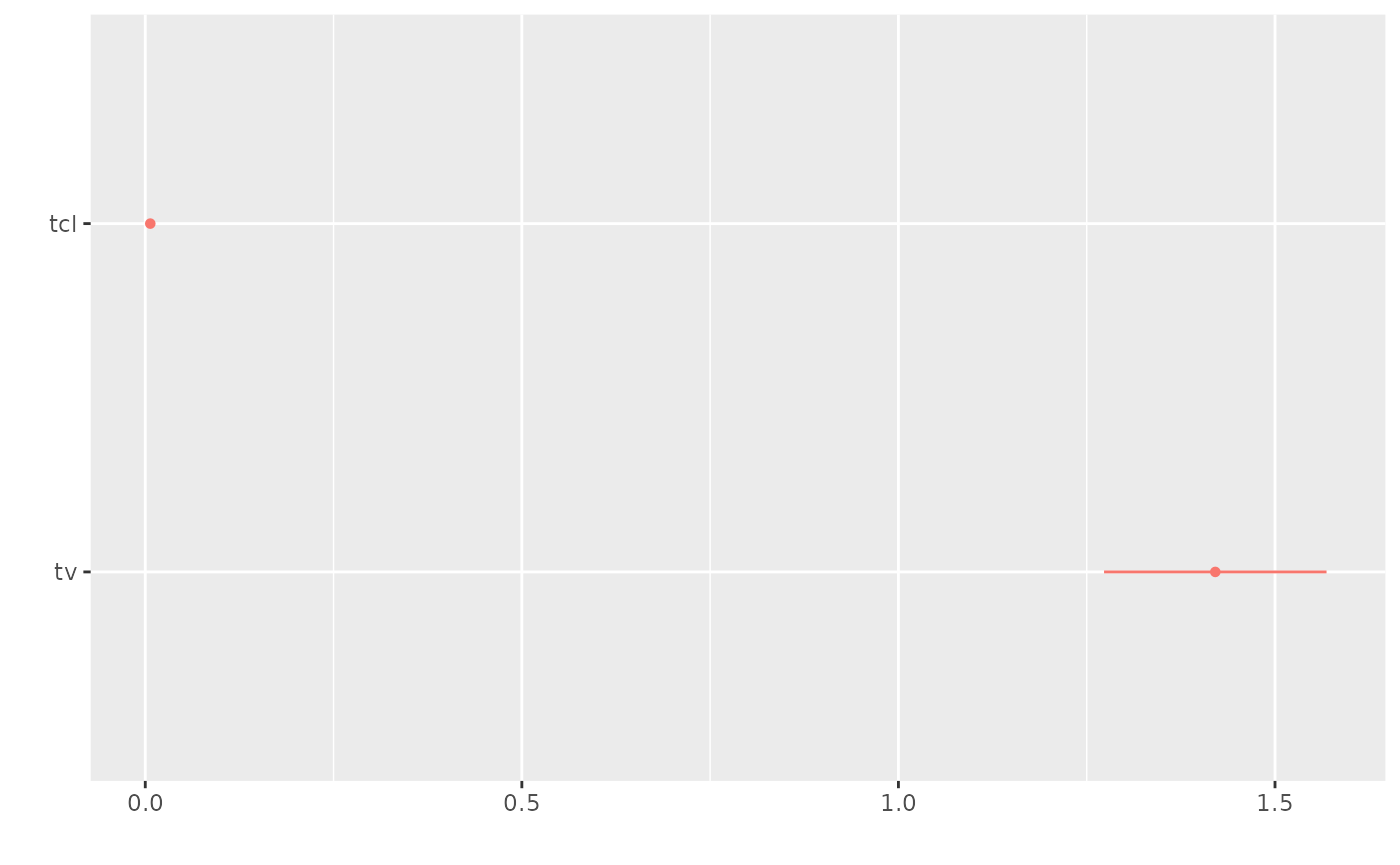
Huxtable
This allows easy creation of report ready tables in many formats including word.
Huxtable relies on the broom implementation
| Phenobarbitol | |
|---|---|
| tcl | -5.011 |
| (0.077) | |
| tv | 0.351 *** |
| (0.053) | |
| sd__eta.cl | 0.511 |
| (NA) | |
| sd__eta.v | 0.388 |
| (NA) | |
| cor__eta.v, eta.cl | 0.987 |
| (NA) | |
| add.err | 2.836 |
| (NA) | |
| N | 155 |
| logLik | -487.073 |
| AIC | 986.147 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | |
You can also use huxtable to compare runs:
huxreg('SAEM'=fit.s, 'FOCEi'=fit.f)| SAEM | FOCEi | |
|---|---|---|
| tcl | -5.011 | -5.006 |
| (0.077) | (0.083) | |
| tv | 0.351 *** | 0.330 *** |
| (0.053) | (0.061) | |
| sd__eta.cl | 0.511 | 0.502 |
| (NA) | (NA) | |
| sd__eta.v | 0.388 | 0.396 |
| (NA) | (NA) | |
| cor__eta.v, eta.cl | 0.987 | 0.980 |
| (NA) | (NA) | |
| add.err | 2.836 | 2.811 |
| (NA) | (NA) | |
| N | 155 | 155 |
| logLik | -487.073 | -486.773 |
| AIC | 986.147 | 985.546 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||
A word-based table can also be easily created with the tool:
library(officer)
library(flextable)
ft <- huxtable::as_flextable(tbl);
read_docx() %>%
flextable::body_add_flextable(ft) %>%
print(target="pheno.docx")Which produces the following word document.
Happy tidying!